


مقدمه
كنترلرهای ترافیك هوایی نقش مهمی در جداسازی هواپیماها در حریم هوایی و سطح فرودگاه دارند و مقدار قابل توجهی از مكالمات بین كنترلرها و خلبانان از طریق كانالهای رادیویی است. لذا رونویسی خودكار این مكالمات نه تنها باعث بهبود امنیت سیستم بلكه باعث پیشرفت عملكردهای عملیاتی و نظارت بر انطباق اطلاعات میشود.
با این حال سیستمهای بازشناسی گفتار خودكاری كه تا به امروز پیشنهاد شده اند دقت لازم برای استفادههای عملی را دارا نبوده اند.عواملی مانند كانال های رادیویی نویز دار ، سرعت تكلم بالا و لهجههای متنوع چالشهایی را برای توسعه بازشناسی گفتار برای كنتلرهای ترافیك هوایی به وجود میاورند اما از سوی دیگر این مكالمات دارای واژگان خاص و مشخص و همینطور عبارتهای استانداردی هستند كه میتوان از آنها برای جهت دهی به الگوریتمها و تقویت آنها در این زمینه استفاده كرد.
تشخیص گفتار خودكار برای كنترل ترافیك هوایی
پیشینه پژوهش
جدید ترین مدلهای تشخیص گفتار خودكار، برای دامنه لغات وسیع، از مدلهای اچ ام ام استفاده كرده اند. اخیرا از مدلهای تركیبی اچ ام ام با مدلهای جی ام ام و یا شبكه های عصبی عمیق استفاده كرده اند و به تازگی، مدلهای سر به سر تشخیص گفتاری كه از شبكه های عصبی عمیق استفاده میكنند پیشرفت های قابل توجهی در افزایش دقت مدلهای تشخیص گفتار داشته اند.
یكی از مزایای كلیدی مدلهای سر به سر در مقابل راهكار های كلاسیك مانند مدلهایی كه بر پایه اچ ام ام هستند سهولت آموزش مدل است، زیرا آنها به خط لوله های پیچیده و مراحل پردازش فوق مهندسی شده نیاز ندارند. با وجود چندین تولكیت متن باز تشخیص گفتارخودكار محققان میتوانند مدلهای متنوعی را بر پایه مدلهای یادگیری عمیق نوشته و با آن تطبیق دهند.
دقت مدلهای تشخیص گفتار خودكار به میزان دادههای برچسب گذاری شده بستگی دارد. میزان دادههای صوتی رونوشت شده عرصه مكالمات خلبان در مقابل دیگر عرصه های تشخیص گفتار خودكار بسیار ناچیز است. پس برای حل این موضوع ما از روش نیمه نظارت شده استفاده میكنیم كه باعث كاهش بیست و پنج درصدی نرخ خطای كلمه میشود. همچنین محققان از مسیر های هوایی پرواز نیز برای افزایش متن نوشته به مدلها استفاده كرده اند كه باعث كاهش پنجاه درصدی میزان خطای فرمان شد اما تغییر چشم گیری در میزان خطای كلمه حاصل نشد.
كار های پیشین همچنین از فرهنگ لغت كوچك تری نسبت به بقیه عرصه ها استفاده كرده اند تا بتوانند مدلهای زبانی بهتری را توسعه بدهند كه نتیجه این امر افزایش بیست درصدی دقت مدل را در پی داشته است.
سهم این مقاله
در این مقاله ما مدل تشخیص گفتار خودكاری را توسعه میدهیم كه مكالمات خلبان با برج مراقبت را به صورت متن رونویسی میكند. مدل پیشنهاد شده بر اساس ساختار سر به سر تشخیص گفتار به همراه یك شبكه عصبی عمیق است كه نسبت به مدلهای مرسومی كه بر پایه رویكرد های اچ ام ام هستند مزایایی را داراست. مدلهایی كه بر پایه اچ ام ام هستند متشكل از چندین ماژول مختلف ) مدل زبانی ، مدل تلفظی ، و غیره ( هستند كه هر ماژول به صورت جداگانه بهینه سازی میشود و تابعی كه این ماژول هارا مرتبط میكند لزوما بهینه بودن روابط را تضمین نمیكند.
در مقابل ، یك مدل سر به سر چندین ماژول متفاوت را فقط با یك شبكه عصبی عمیق جایگزین میكند كه بدون نیاز به تنظیم دستی پیشرفته حالات، نگاشت مستقیم سیگنالهای زبانی را به زنجیرهای از كاراكترها مقدور میسازد و همینطور آموزش یك مدل سر به سر بسیار آسانتر از روشهای مرسوم قدیمی است. علاوه بر آموزش مدل با رونوشت ها ما دقت مدل را با آموزش انتقالی و تنظیم دقیق پارامترها كه از قبل بر روی دادههای زبان گفتاری آموزش داده شده اند مقایسه میكنیم.
به دلیل وابستگی دقت مدل به میزان دادههای ورودی ،ما مجموعه دادگان مختلفی را از منابع گوناگون جمع آوری و در مدلها استفاده كردهایم تا تاثیر مجموعه دادگان مختلف را برروی آموزش مدل درك كنیم. به محض رونویسی شدن فایلهای صوتی ،بیشتر برنامه ها نیاز به استخراج اطلاعات از رونوشت ها دارند؛ برای حل این موضوع و جداسازی دقیق اطلاعات عملیاتی از رونوشت ها ما روشی را به كمك جدید ترین تكنیك های پردازش زبان طبیعی در پیش خواهیم گرفت. ما همچنین در نبود داده مرجع برای تعیین معیارعملكردمان كه پایه و نیاز گرفتن تصمیمات در استفاده از دادههای رونوشت شده است روشی به نام عدم قطعیت نمره نرمال شده را پیشنهاد میدهیم.
مدل تشخیص گفتار خودكار
مدل تشخیص گفتاری كه از آن استفاده میكنیم مدلی بر پایه دیپ اسپیچ است و برای انالیز خود از پیاده سازی دیپ اسپیچ موزیلا استفاده خواهیم كرد.
نمای كلی مدل
شكل ۱ ساختار كلی سیستم تشخیص گقتار را نمایش میدهد. این شكل متشكل از ماژول استخراج ویژگی ، مدل صوتی ، مدل زبانی و ماژول رمزگشایی هست. ماژول استخراج ویژگی سیگنال های صوتی را به عنوان ورودی دریافت میكند و مضاربی وابسته به طیف فركانسی اش را به عنوان خروجی به این صورت میدهد: تمامی زنجیره زمانی صوتی به بخش های كوچكتر سی و دو میلی ثانیه ای با بیست میلی ثانیه همپوشانی تقسیم شده و هر بخش وابسته به بردار ویژگی اش با ام اف سی سی اش در ارتباط خواهد بود.
ام اف سی سی هر بخش بردار ویژگی ای را میسازد كه به عنوان ورودی مدل صوتی استفاده خواهد شد. مدل صوتی، یك شبكه عصبی بازگشتی است كه آموزش میبیند تا بر اساس دنباله ورودی بردار ویژگی، دنباله ای از احتمالات كاراكتر هارا به عنوان خروجی تولید كند. مدل زبانی احتمال دنباله ای از كاراكتر هارا بر پایه داده آموزشی مستقل از سیگنال صوتی به عنوان خروجی میدهد. و در نهایت ماژول رمزگشایی خروجی مدل صوتی را با مدل زبانی تركیب كرده تا متن رونوشت شده را تعیین بكند.
مدل صوتی
مدل صوتی ،یك شبكه عصبی بازگشتی است.این شبكه كه متشكل از پنج لایه پنهان است سه لایه اول آن غیر بازگشتی بوده كه لایه اول ورودی ام اف سی سی را برای بازه زمانی خاصی دریافت میكند. برای همه لایه ها غیر از لایه آخر از تابع فعال سازی رلو استفاده شده است.
برای چهارمین لایه از لایه فید فوروارد بازگشتی به جای لایه عصبی دوطرفه بازگشتی برای كاهش زمان محاسبات استفاده شده است. لایه آخر لایه ی غیر بازگشتی خروجی است كه احتمالات كاراكترها را بر اساس تابع سافت مكس نتیجه میدهد. از تابع فقدان سی تی سی نیز برای حدس زدن اشتباهات در حین آموزش استفاده میشود.
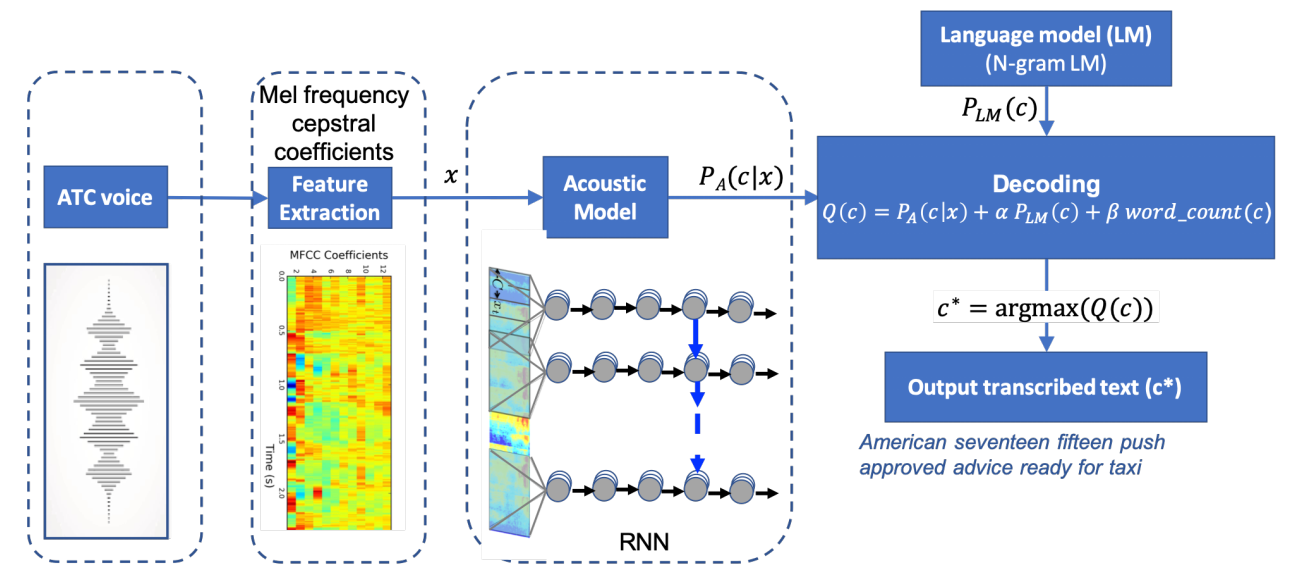
شكل ۱: ساختار مدل سيستم تشخيص گفتار خودكار
مدل زبانی
آموزش مدل صوتی برای مكالمات خلبان با برج مراقبت به دلیل كمبود دادههای رونوشت شده كاری پر از چالش است. برای همین ما از مدل زبانی ای كه برای این مكالمات طراحی شده استفاده میكنیم. مدل زبانی، توزیع احتمال رشته ای از كلمات است كه در مرحله رمزگشایی استفاده میشود. برای این منظور ما از مدل زبانی اِن گرام استفاده میكنیم زیرا با استفاده از كتابخانه هایی مثل KenLM به راحتی و با دقت بالا میتواند آموزش ببیند.
مرحله رمزگشایی
مرحله رمزگشایی بر حسب احتمالات خروجی حاصل از مدلهای زبانی و صوتی، محتمل ترین دنبالهای از كلمات را به خروجی میدهد. فرض كنید PA(c | x) نشان دهنده احتمال رشته ای كاراكترها مانند رشته c برحسب ورودی x برای مدل صوتی، و PL(c) نشان دهنده احتمال رشته از كاراكترها بر حسب مدل زبانی باشد. هدف مرحله رمزگشایی ماكسیمم كردن نمره اطمینان (Q(c)) برای رشته ای از كاراكترها خواهد بود :
![]()
كه در اینجا آلفا و بتا وزنهایی هستند كه تاثیر مدلهای صوتی و زبانی و تعداد كلمات را متعادل میكنند. (c(Q با استفاده از الگوریتم search beam تعیین میشود. و مقدار بهینه آلفا و بتا با استفاده از آنالیز پارامتری به طوری كه نرخ خطای كلمه مینیمم شود، مشخص میشود.
مدل برای مكالمات خلبان با برج مراقبت
منابع داده
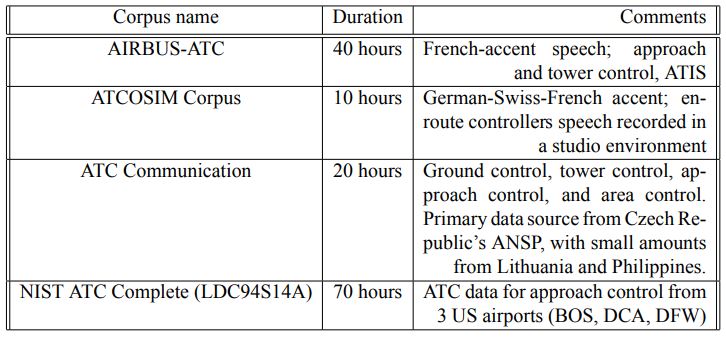
براي آموزش مدل از تركيب چهار منبع داده زير استفاده شده است:
معيار عملكرد
نرخ خطای كلمه از پركابردترین معیار های اندازهگیری مدلهای تشخیص گفتار خودكار است. و با توجه به مجموع تعداد كلمات متن رونویسی شده در مقایسه با متن مرجع كه به اشتباه جایگذاری ، حذف و یا وارد شده اند، تقسیم بر تعداد تمام كلمات متن مرجع تعریف میشود:
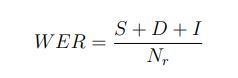
سرعت رونویسی نیز از دیگر معیارهای مهم عملكرد مدل محسوب شده و بر حسب (RTF) كه حاصل تقسیم مدت زمان صوت ورودی بر مقدار زمانی كه نیاز است تا داده پردازش شود است، اندازه گیری میشود. RTF حاصل از مدل تولید شده تقریبا 0/3 بوده كه به این معناست كه میتواند در مكالمات زنده نیز مورد استفاده قرار گیرد.
انواع مدل
از سه مدل زير براي انجام پژوهش استفاده ميكنيم:
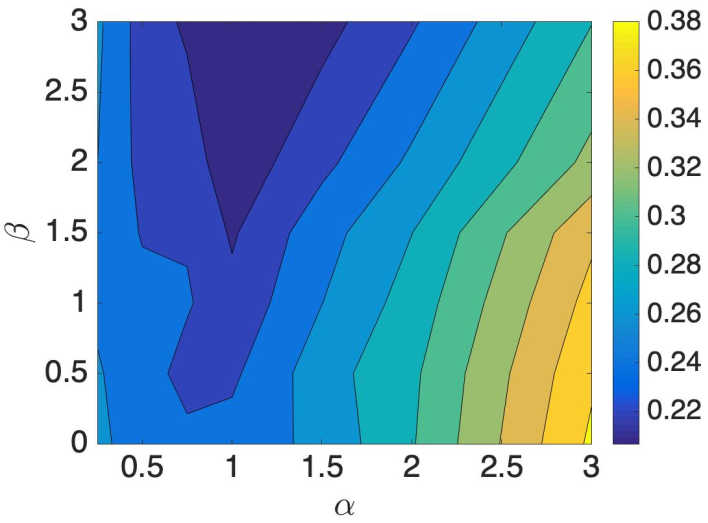
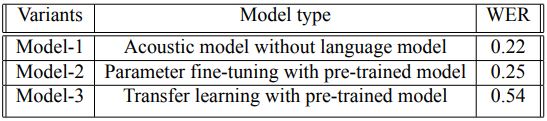
مدل- ۱ : مدل زبانی و مدل صوتی كه در مدل صوتی بهینه تعداد نورون های هر یك از لایههای پنهان با استفاده از آنالیز پارامتری ۶۵۰ نورون و مقدار بهینه آلفا و بتا در مدل زبانی با امتحان كردن همه تركیبهای مقادیر ممكن بین بازه ای خاص از اعداد كه كمترین نرخ خطای كلمه را دارا باشد با توجه به شكل ۲ براورد شد. و با انالیز پارامتری ای مشابه مقدار N برای gram-N مدل زبانی، ۴ بدست آمد.
مدل- ۲ :پالایش پارامترهای یك مدل از قبل آموزش داده شده ما از مدل صوتی ای كه برای مكالمات معمولی آموزش داده شده بود استفاده كرده و پارامترهای شبكه عصبی اش را با استفاده از منبع داده Speech ATC پالایش كردیم. در این مدل هر لایه دارای ۲۰۴۸ نورون بوده و نرخ خطای كلمه بر روی مكالمات معمولی ۸/۰ است. عملیات بهینه سازی طی چهار epoch با نرخ یادگیری ای كوچك (ده به توان منفی پنج) برای گرادیان دیسنت انجام شد. و مانند مدل قبل از مدل زبانیای كه قبلا بر روی منبع داده ATC آموزش داده شده بود استفاده كردیم.
مدل- ۳ :یادگیری انتقالی با یك مدل آموزش دیده شده از قبل یادگیری انتقالی كمك زیادی به برنامههای مرتبط با یادگیری ماشین مخصوصا زمانی كه حجم دادههای برچسب گذاری شده كم است میكند. در این زمینه ما از مدل از قبل آموزش دیده شده ای استفاده كردیم كه برای مكالمات گفتاری معمولی استفاده میشده است. ما پارامترهای سه لایه اول مدل از قبل آموزش دیده شده را فریز كرده و پارامترهای دولایه باقی مانده را با استفاده از منبع داده Speech ATC دوباره آموزش دادیم.
عملكرد مدلها
خلاصه ای از نرخ خطای كلمه مدلها در جدول زیر نمایش داده شده است:
استخراج اطلاعات عملياتی
مكالمات خلبان با برج مراقبت دارای اطلاعات عملیاتی مهمی مانند اطلاعات باند و شناسه پرواز هستند كه در تصمیم گیری نقش مهمی را ایفا میكنند. در این بخش از یك مدل آماری برای استخراج شناسه و یك مدل قاعده مند گرامری برای استخراج اطلاعات باند فرودگاه استفاده میشود. برای استخراج شناسه از روشی به نام (NER) كه یك تكنیك استاندارد پردازش زبان طبیعی است استفاده كرده و هدف از استفاده از آن تشخیص و گروه بندی شناسه در صورت وجود میباشد. برای پیاده سازی مدل NER از كتابخانه Spacy استقاده میكنیم كه نكته كلیدی در استفاده از این كتابخانه تشخیص شناسهها در صورت وجود خطا در متن رونویسی شده خواهد بود.
معیارهای عملکرد
دقت مدل با استفاده از سه معیار اندازه گیری میشود: score 1-F, Recall و Precision. ما چند نكته را در تعریف این سه معیار لحاظ میكنیم: اگر A تعداد دفعاتی باشد كه در داده تست شناسهای وجود داشته نداشته و مدل نیز شناسهای تشخیص نداده باشد و B تعداد دفعاتی باشد كه در داده تست شناسهای وجود داشته اما مدل چیزی را تشخیص ندهد و C تعداد دفعاتی باشد كه در متن داده شده شناسهای وجود نداشته اما مدل به اشتباه شناسهای را تشخیص دهد و D .و E .تعداد دفعاتی باشند كه شناسه درست و نادرست در متنی كه در آن شناسه وجود دارد تشخیص داده شده باشد. بیان ریاضی آن به این صورت خواهدبود:
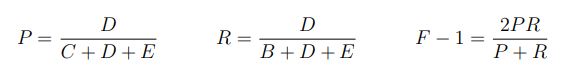
نتيجهگيری
استفاده از مدل زبانی ان گرام بعلاوه مدل صوتی میتواند دقت را تا ۲۶ درصد افزایش بدهد. استفاده از منبع دادههای مختلف و گسترده در آموزش مدل میتواند به مدل قابل تعمیم تری منجر شود. score 1-F مدل استخراج شناسه بر روی متن اصلی ۹۵/۰ و بر روی متن تولید شده توسط مدل ۶۹/۰ بوده است و به همین ترتیب score 1-F مدل استخراج اطلاعات باند فرودگاه بر روی متن اصلی ۱ و بر روی متن تولید شده توسط مدل ۹۵/۰ خواهد بود. این پیشرفت ها به طور بالقوه می توانند دقت رونویسی را بهبود بخشند و كاربردهای عملی را از نظارت بر ایمنی در زمان واقعی تا دستیارهای گفتاری برای كنترل كنندههای ترافیك هوایی را ممكن سازند.
مراجع
Automatic Speech Recognition for AirTraffic Control Communications