

مقدمه
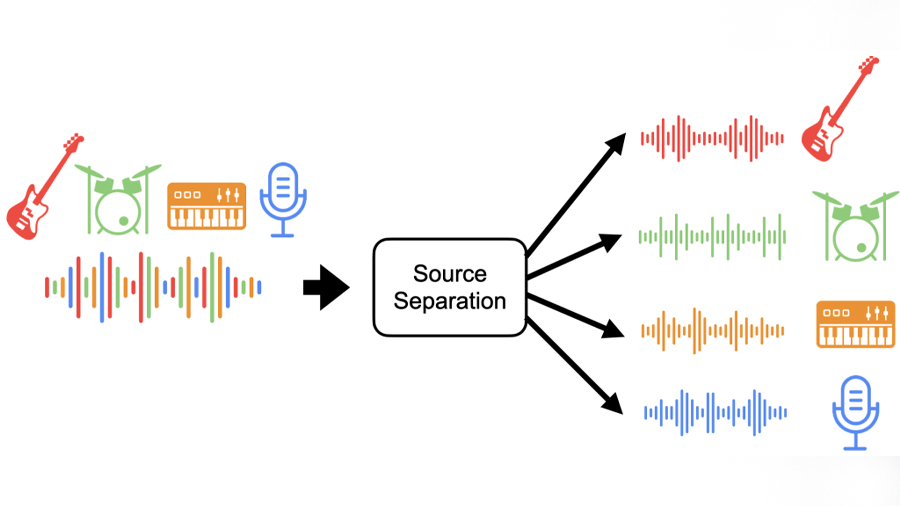
جداسازی منابع صوتی (مانند زمانی كه چند شخص همزمان صحبت می كنند) یكی از مباحثی است كه پژوهش های زیادی در زمینه آن انجام شده است. روش های متعددی برای این كار وجود دارد. یكی از بهترین روش هایی كه تاكنون ارائه شده است، استفاده از شبكه عصبی عمیق است. LSTM یك نوع شبكه عصبی بازگشتی است كه برای سیگنال های طولانی بكار می رود. در این روش به دلیل ارتباط كامل میان لایه ها، آموزش شبكه كند است و اندازه مدل بزرگ خواهد شد. یك روش دیگر استفاده از شبكه عصبی كانولوشنال است. این روش برای سیگنال های طولانی منجر به عمق بیشتر شده و فرآیند آموزش را سخت تر می كند. در مقاله مطالعه شده دنبال روشی جدید هستیم كه با تركیب این دو شبكه عصبی بتوانیم مدل كارآمدتری بسازیم. ابتدا ساختار هر یك از شبكه ها را بررسی كرده، سپس درباره انواع شیوه اتصالات آن ها بحث می كنیم و بهترین روش را برای ساختار جدید ارائه می كنیم. سپس این شبكه را برای جداسازی صدای خواننده در موسیقی بكار می بریم.
Multi-Scale Multi-Band DenseLSTM
Multi-Scale Structure
در میان انواع شبكه های عصبی كانولوشنال، DenseNet عملكرد قابل قبولی داشته است. ایده اصلی این شبكه، بهبود جریان اطلاعات میان لایه ها با استفاده از تبدیلی غیرخطی است كه ۲ ورودی آن، خروجی لایه های پیشین است. این تابع شامل نرمالیزه كننده دسته ای،یكسوكننده و كانولوشن با k نگاشت است. برای بررسی داده های طولانی تر از یك كاهنده نمونه استفاده می كنیم. سپس در پایان از افزاینده نمونه استفاده كرده تا داده را با وضوح اولیه بازسازی كنیم.
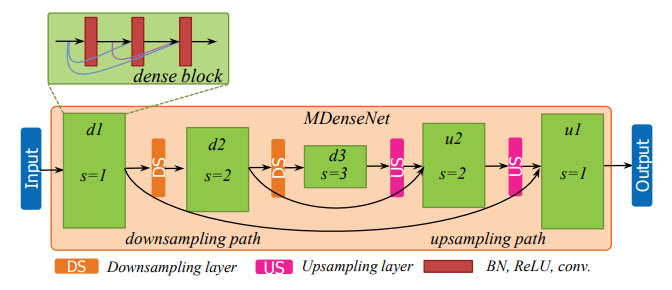
شكل ۱:ساختار Multi-Scale
Multi-Band Structure
برخلاف تصاویر، در باندهای فركانسی مختلف سیگنال های صوتی شاهد الگوهای متفاوت هستیم. بنابراین یك روش بهبود عملكرد شبكه، بكارگیری الگوهای مختص به هر باند فركانسی است.
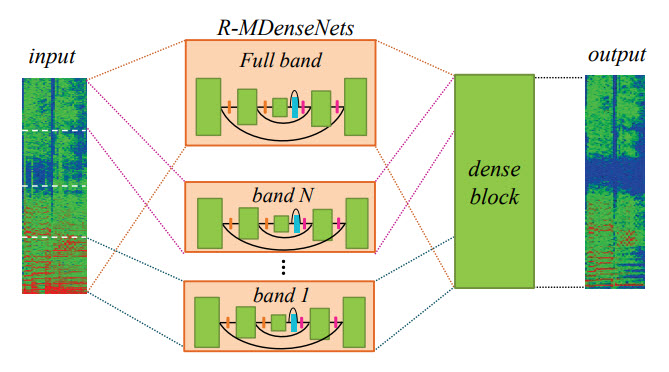
شكل ۲:ساختار Multi-Band
ترکیب MMDenseNet و LSTM
تركیب دو سیستم و استفاده از مزایای هر كدام منجر به عملكرد بهتر سیستم در مقایسه با عملكرد هر كدام به تنهایی خواهد شد. هنگامی كه از دو ساختار متفاوت استفاده می كنیم، این بهبود عملكرد در مقایسه با استفاده از یك ساختار با پارامترهای متفاوت بیشتر خواهد بود. برای تركیب دو ساختار MMDenseNet و LSTM سه نوع روش را در نظر می گیریم و عملكرد آن ها را مقایسه می كنیم. این سه روش عبارتند از اتصال دو بلوك به صورت موازی (P) و اتصال به روش سری به طوری كه یا ابتدا از بلوك MMDenseNet استفاده كنیم (Sa) و یا از بلوك LSTM (Sb) .
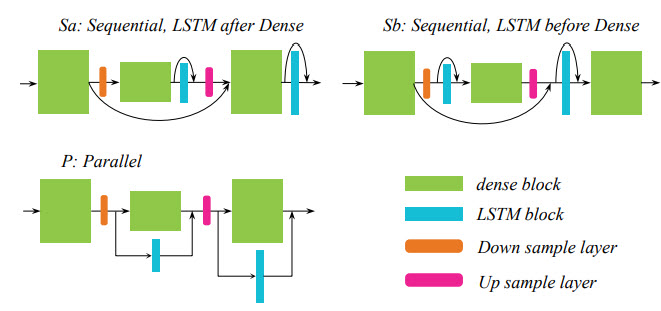
شكل ۳ :تركيب دو ساختار MMDenseNet و LSTM
آزمایش
جزئیات ساختار
در این ساختار سیگنال ورودی به سه باند فركانسی (۴ .۱ كیلوهرتز و ۱۱ كیلوهرتز) تقسیم می شود. بلوك های LSTM نیز به تعداد محدود و پس از بلوك های افزاینده u2 قرار می گیرند كه باعث می شود سایز مدل بزرگ نشود.
داده ها
ساختار پیشنهادی روی داده های DSD100 و MUSDB18 ارزیابی شده كه دارای ۱۵۰ آهنگ شامل چهار منبع بیس، درام، آواز و بقیه سازها و همچنین مخلوط آن هاست كه در فرمت استریو و فركانس ۴۴ .۱ كیلوهرتز ضبط شده است. به عنوان ورودی، از تبدیل فوریه سیگنال با ۴۰۹۶ نمونه در هر فریم با ۷۵ درصد هم پوشانی استفاده شده است. شبكه ها طوری آموزش داده شده اند كه خطای میانگین مربعات به حداقل برسد.
صحت ساختار
برای سنجش صحت ساختار پیشنهادی، از معیار SDR استفاده می كنیم. این معیار بیانگر نسبت انرژی سیگنال به انرژی اعوجاج است. مقدار بیشتر این پارامتر بیانگر كیفیت بهتر خروجی ماست.
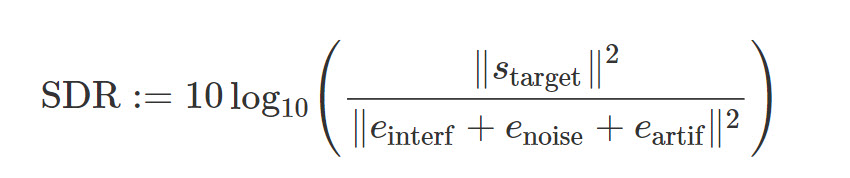
جدول زیر مقدار SDR را برای سه ساختار موازی و سری نوع اول و دوم نشان می دهد.
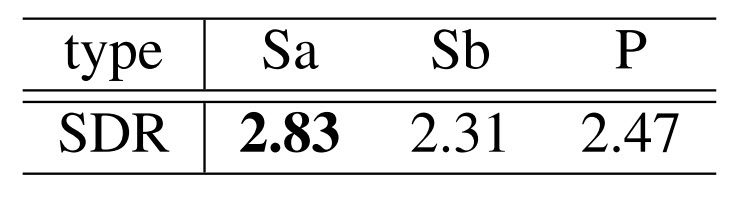
جدول ۱ :معیار SDR در سه ساختار
در جدول زیر معیار SDR برای داده های DSD100 و روی شبكه های متفاوت نشان داده شده است.
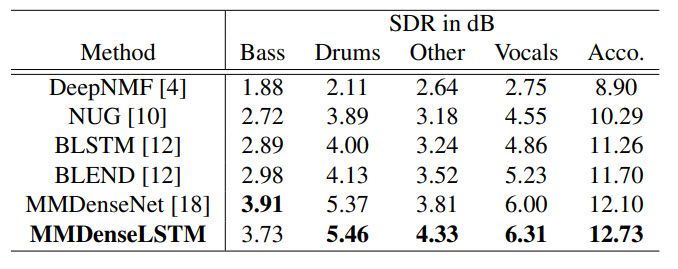
جدول ۲ :معیار SDR در داده های DSD100
و در جدول زیر معیار SDR برای داده های MUSDB18 و روی شبكه های متفاوت نشان داده شده است.
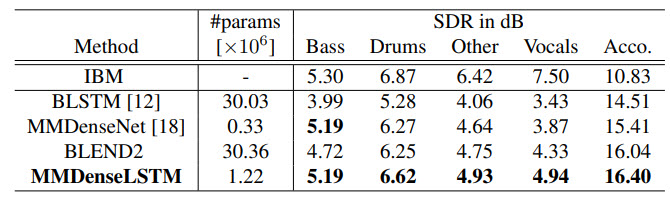
جدول ۳ :معیار SDR در داده های MUSDB18
نتیجه گیری
همانطور كه مشاهده كردیم، شبكه عصبی حاصل از تركیب دو نوع شبكه عصبی متفاوت منجر شد كه به خروجی هایی با كیفیت مناسب برسیم. یكی از كاربردهای عملی شبكه آموزش داده شده، جداسازی صدای خواننده ها از موسیقی است كه قصد داریم آن را به صورت یك سرویس پیاده سازی كرده به طوری كه كاربر به یك بات تلگرامی موسیقی مورد نظر خود را ارسال كرده و دو فایل صوتی جداگانه شامل صدای خواننده و صدای سازها را دریافت كند.
مراجع
Takahashi et al., ”MMDenseLSTM: An efficient combination of convolutional and recurrent neural networks for audio source separation”