


پیکره متنی ناب
پیکره متنی بزرگ از مهمترین نیازهای آموزش مدلهای شبکه عصبی عمیق به خصوص شبکههای بر پایه ترنسفورمر است. ضرورت این مسئله به خصوص برای زبانهای با منابع کمتر – مثل فارسی – بیشتر احساس میشود. ما، تیمی از آزمایشگاه پردازش زبان طبیعی و گفتار دانشگاه صنعتی شریف (به سرپرستی دکتر حسین صامتی) به همراه محققان مرکز نوآوری شرکت عصرگویشپرداز برای این مساله راهحل پیکره ناب را معرفی کردهایم. این پیکره مجموعه پاکسازی شده و قابل استفاده مستقیم برای محققان حوزه پردازش زبان طبیعی در فارسی است. این مجموعه شامل حدود 130 گیگابایت دیتا متنی شامل 250 میلیون پاراگراف و 15 میلیار کلمه است.
ناب
در سال های اخیر، پردازش زبان طبیعی به عنوان یکی از مهمترین حوزه های یادگیری ماشین و یادگیری عمیق مورد توجه قرار گرفته است. مدل های پایه در این حوزه همان مدل های زبانی هستند که به حجم زیادی از داده متنی نیاز دارند. عملیات آموزش این مدل های زبانی به صورتی است که در آن کلمه یا کلماتی از متن حذف میشود و از مدل خواسته میشود که با توجه به واژگان خود جای خالی را حدس بزند بدین ترتیب مدل زبانی جایگاه مناسب معنایی کلمات موجود در واژگان زبان را میشناسد. معمولا این آموزش به مقدار بسیار زیادی داده متنی تمیز شده نیاز دارد. این موضوع در زبان هایی که منابع متنی آزاد کمتری برای آن وجود دارد بسیار بیشتر احساس میشود. کمبود این منابع متنی باعث میشود که محققان این حوزه نتوانند مدل های زبانی روز دنیا را برای فارسی آموزش دهند.
بزرگترین پیکره متنی پیکره متنی PersianNLP بود که مجموعه ای از حدود 70 گیگابایت متن خام را شامل میشد. این پیکره شامل 8 زیر پیکره به ترتیب زیر بود:
- پیکره Common-Crawl
- پیکره Miras
- پیکره W2C
- پیکره ویکیپدیا فارسی
- پیکره لایپزیک
- پیکره VOA
- پیکره اشعار فارسی
- پیکره موازی فارسی-انگلیسی
با وجود اینکه این داده تا حد خوبی جواب محققان حوزه پردازش زبان طبیعی را میدهد نیاز به داده بیشتر در این حوزه احساس میشد. از طرفی دیگر این پیکره عموما شامل متون رسمی است و کمتر متن غیر رسمی در آن دیده میشود.
در سال های گذشته افراد و سازمان های متعددی سعی داشته اند که برای آسان کردن فرآیند آموزش مدل امکان استفاده و آموزش مدل های موجود در حوزه یادگیری عمیق علی الخصوص پردازش زبان طبیعی را داشته اند. از موفق ترین این سازمان ها میتوان به Huggingface اشاره کرد. این سازمان کتابخانه هایی به زبان پایتون به صورت متن باز تهیه کرده است و بدین ترتیب آموزش مدل های بر پایه یادگیری انتقالی را بسیار آسان تر کرده است. از جمله این کتابخانهها میتوان به transformer و datasets اشاره کرد. این دو کتابخانه که ترتیب برای استفاده و آموزش مدل و خواندن دیتاست های استفاده میشود با یکدیگر ساختار یکپارچهای میسازد که فرآیند آموزش مدل های زبانی را بسیار آسانتر میکند. پیکره های فارسی موجود هیچکدام بر روی مخزن datasets قرار نگرفته اند و نیاز به حضور یک پیکره یکپارچه فارسی در آن فضا احساس میشد.
ما، تیمی از آزمایشگاه پردازش زبان طبیعی و گفتار دانشگاه شریف به سرپرستی دکتر حسین صامتی به همراه محققین مرکز نوآوری شرکت عصرگویش پرداز پیکره متنی ناب را معرفی میکنیم. این پیکره شامل حدود 130 گیگابایت متن تمیز شده کاملا فارسی که متشکل از 250 میلیون پاراگراف و 15 میلیار کلمه است. این پیکره متنی به صورت کاملا متن باز در اختیار همگان قرار داده شده است و محققان حوزه پردازش طبیعی میتوانند به راحتی از آن بهره بجویند. از مزیت های پیکره ناب قرار گرفتن آن بر روی مخزن دیتاست Huggingface است، بدین ترتیب میتوانید تمام یا بخشی از این پیکره را به کمک کتابخانه dataset دانلود کرده و برای آموزش مدل خود استفاده کنید.
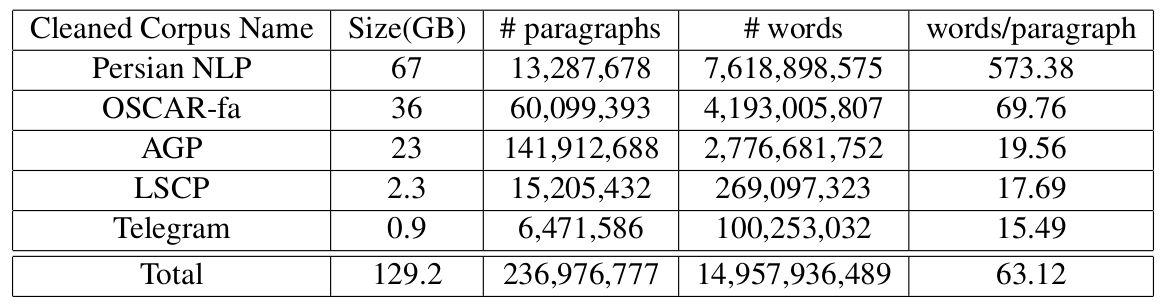
تصویر ۱: اطلاعات کلی پیکره متنی ناب (پس از پاکسازی)
علاوه بر این نسخه خام پیکره ناب به همراه ابزار پاکسازی متن در اختیار عموم قرار گرفته است تا به کمک آن بتوانید پیکره متنی تمیز شده خود را بسازید. همچنین در صورتی که پیکره متنی دارید که میخواهید به اشتراک بگذارید میتوانید به سادگی آن را به پیکره خام ناب اضافه کنید بدین ترتیب کاربران میتوانند علاوه بر استفاده از پیکره متنی شما به صورت جداگانه از آن در کنار بقیه پیکره های متنی فارسی نیز استفاده کنید. برای اطلاعات بیشتر راجع به پیکره متنی ناب به این لینک مراجعه کنید.
جزئیات ناب
در این قسمت به بررسی تعدادی از جزئیات مربوط به پیکره متنی ناب میپردازیم. برای اطلاعات بیشتر راجع به جزئیات پیکره ناب به مقاله ناب مراجعه کنید. این پیکره از 5 زیر پیکره تشکیل شده است که جزئیات آن در تصویر 1 آمده است. در ادامه توضیحات مختصری راجع به هر کدام از پیکره ها داده میشود.
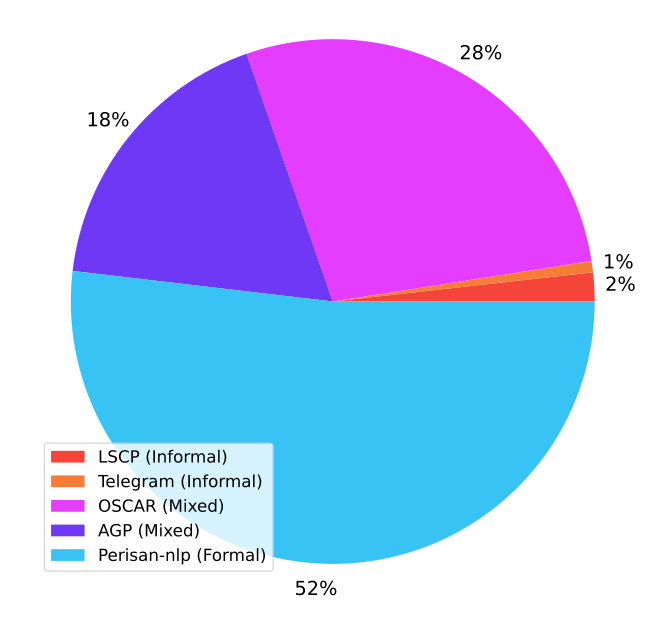
تصویر ۲: توزیع دادگان پیکره ناب
پیکره PesianNLP
همانطور که در قسمت قبل گفته شد این پیکره شامل حدود 70 گیگابایت متن فارسی است.
پیکره OSCAR-fa
پیکره OSCAR یک پیکره چند زبانه است که شامل زبان های مختلفی از جمله فارسی است. نسخه اصلی این پیکره 38 گیگابایت دیتای فارسی است که در پیکره ناب از نسخه به هم نخورده با حذف جملات تکراری استفاده میکنیم. این پیکره شامل متون رسمی و غیررسمی است.
پیکره AGP
پیکره شرکت عصرگویش پرداز که حدود 25 گیگابایت است شامل متون رسمی و غیر رسمی است. این پیکره تا قبل از استفاده شدن در ناب به صورت خصوصی مورد استفاده شرکت عصرگویش پرداز بود که از این پس به عنوان قسمت از پیکره ناب در دسترس عموم قرار گرفته است. امیدواریم موارد این چنینی در بین شرکت های فعال در زمینه هوش مصنوعی بیشتر انجام شود و به گونه ای ادامه دهنده راهی شوند که اولین بار در این ابعاد توسط شرکت عصرگویش پرداز در ایران ایجاد شده است.
پیکره LSCP
دیتاست محاوره ای LSCP که توسط خجسه و همکاران معرفی شد شامل 5 گیگ دیتا محاوره ای است که جزو معدود دادگان غیررسمی حجم بالای زبان فارسی بود. به کمک این دیتاست پیکره ناب شامل قسمت بزرگتری دادگان غیررسمی به نسبت مجموعه دادگان قبلی شده است.
پیکره Telegram
حدود 1 گیگ داده غیررسمی توسط تیم تهیه کننده ناب جمع آوری شده از شبکه پیامرسانی تلگرام که شامل متون محاوره ای و غیررسمی است به دادگان ناب اضافه شده است که حجم دادگان رسمی افزایش بیایبد.
نتیجهگیری
پیکره متنی ناب به عنوان بزرگترین پیکره تمیز شده فارسی آزاد شامل ۱۳۰ گیگابایت داده متنی کاملا فارسی در اختیار محققین حوزه پردازش طبیعی قرار گرفته است. امید است با همیاری یکدیگر فضای کار را برای پردازش زبان طبیعی در فارسی آسانتر کنیم. مرکز نوآوری شرکت دانش بنیان عصر گویش پرداز، واقع در دانشگاه صنعتی شریف، آماده است تا با کمک این پیکره و تامین بستر مناسب، ایدههای پژوهشی محققان را به عرصه واقعیت پرورش دهد.
در صورتی که تمایل دارید به جمع پیکره ناب بپیوندید و به فعالیت و پرورش ایدههای خود در مرکز نوآوری ما علاقهمندید، اطلاعات خود را در فرم زیر وارد کنید.
برای مطالعه بیشتر به لینک های زیر مراجعه کنید:
https://huggingface.co/datasets/SLPL/naab-raw
https://huggingface.co/datasets/SLPL/naab
https://arxiv.org/abs/2208.13486
ارجاعات
Hadi Abdi Khojasteh, Ebrahim Ansari, and Mahdi Bohlouli. 2020. Lscp: Enhanced large scale colloquial persian language understanding. arXiv preprint arXiv:2003.06499.