


مقدمه
در این پست قصد داریم به روشهای مختلف ارائه شده در پرداختن به مسألهی پرسش و پاسخ مکالمهای با استفاده از بازنویسی سؤالات بپردازیم. پس از خواندن این پست، شما با هوش مصنوعی مکالمهای آشنا شده و همچنین سه تا از مهمترین روشهای ارائه شده برای چالش بازنویسی سؤالات را فراخواهید گرفت.
برای شروع و برای کسانی که پیش زمینه کافی ندارند، پرسش و پاسخ مکالمهای زیرشاخهای از علم پردازش زبان طبیعی است که در آن، ماشین بایستی در بستر یک مکالمه به سؤالات کاربر پاسخ دهد. به عبارت دیگر میتوان آن را جزوی از چالش پرسش و پاسخ و ماشینی دانست که حول یک مکالمه شکل میگیرد. همانند دیگر مسائل حوزهی هوش مصنوعی، این چالش هم دارای مجموعه دادگان برای آموزش و تست مدلهای این حوزه میباشد که از معروفترین آنها میتوان به QuAC و CoQA اشاره کرد.
بازنویسی سؤالات چیست؟
یکی از چالشهای اساسی در پرسش و پاسخ مکالمهای، وابستگی سؤالات کاربر به یکدیگر و ارجاعهای مکرر به سؤالات قبلی است. بنابراین مدلهای ارائه شده برای این چالش، بایستی بتوانند راه حلی برای فهم و درک ارجاعها ارائه داده و سپس به ارائه پاسخ خود بپردازند. برای فهم ارجاعها و برطرف کردن آنها راهحل های مختلفی ارائه شده است که یکی از آنها بازنویسی صورت سؤال میباشد. در سال 2019 یک دیتاست با عنوان CANARD ارائه شد که در آن قسمتی از سؤالات دیتاست QuAC به صورت یک سؤال خودمشمول برطبق آن مکالمه بازنویسی شده است. به طور مثال یک مکالمه میتواند به شکل زیر باشد:
+ پایتخت ایران کجاست؟
— تهران
+ ترکیه چطور؟
— استانبول
همانطور که مشاهده کردید، برای پاسخ به سؤال دوم، ماشین بایستی بفهمد که منظور کاربر از سؤال دوم پرسیدن در مورد «پایتخت» کشور ترکیه میباشد. بنابراین احتمالا اگر به دیتاست CANARD [1] مراجعه کنیم، مکالمهی بالا به شکل زیر بازنویسی شده است:
+ پایتخت ایران کجاست؟
— تهران
+ پایتخت ترکیه چطور؟
— استانبول
بنابراین همانطور که گفته شد، یک مجموعه از مدلهای حوزهی هوش مکالمهای، سعی میکنند ابتدا با استفاده از دیتاستهای بازنویسی سؤالات، مدلی برای بازنویسی سؤالات ارائه داده، و سپس با استفاده از آن مدل یک سؤال خود-مشمول بدست آورده و این سؤال را به مدلهای معمول پرسش و پاسخ بدهند و پاسخ را ارائه کنند. در این صورت مسألهی پرسش و پاسخ مکالمهای به دو مسألهی دیگر، یعنی بازنویسی سؤالات و پرسش و پاسخ، شکسته میشود.
حال چگونه میتوان مدلی آموزش داد تا سؤالات یک مکالمه را بازنویسی کند؟ این سؤالی است که در ادامه قرار است به آن بپردازیم و تعدادی از مهمترین روشهای ارائه شده در این حوزه را بررسی کنیم.
مدلهای بازنویسی سؤالات
ترنسفورمر ++
این مدل برپایه ترنسفورمرها میباشد و به روش رمزنگار-رمزگشا یا دنباله به دنباله آموزش دهی میشود. به عبارت دیگر در هنگام آموزش این مدل، دنبالهی کلمات ورودی، همان سؤالات مبهم و دارای ارجاع هستند و دنبالهی هدف، سؤالات خود-مشمول و بدون ارجاعات میباشند. تصویری از رمزگشای این مدل در شکل ۱ آمده است. این مدل در ابتدا با وزندهی اولیهی مدل پیش آموزش دیدهی GPT2 شروع به آموزش میکند و روی امر بازنویسی سؤالات تنظیم دقیق (fine-tune) میشود. همچنین برای آموزش مدل به روش دنباله به دنباله، از تکنیک اجبار معلم (teacher forcing) نیز استفاده شده است و رمزگشایی نیز به روش حریصانه انجام شده.
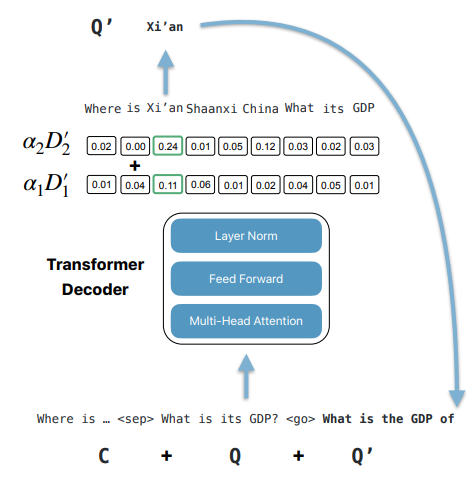
برروی دیتاست TREC CAsT، این مدل به دقت ROUGE برابر با ۹۰ درصد رسیده است.
دستهبندی کلمات
ایدهی اصلی در این روش این است که سعی کنیم سؤال بازنویسی شده را با استفاده از کلمات موجود در سؤالات قبلی و سؤال فعلی بسازیم. این روش از یک دستهبند دودویی استفاده میکند و برای هر یک از کلمات در سؤالات پیشین مکالمه، تصمیم میگیرد که آن کلمه بایستی در سؤال فعلی وجود داشته باشد یا خیر؟
پس از اجرای دستهبندی روی کلمات پیشین، در نهایت کیسهای از کلمات به عنوان سؤال فعلی خواهیم داشت که ممکن است به صورت یک جملهی طبیعی بنظر نرسد. اما به عنوان شهود، مزیت استفاده از این روش نیاز به دادههای کمتر برای آموزش میباشد، چرا که مدلهای دنباله به دنباله، همانند ترنسفورمر++، اصولا نیازمند دادههای بسیار زیاد برای داشتن عملکرد مناسب میباشند، درحالیکه دیتاستهای بازنویسی سؤالات معمولا این حجم داده را براورده نمیکنند.
تصویر معماری این مدل برای بازنویسی سؤالات در شکل ۲ آمده است. همانطور که مشاهده میشود، برای کدگذاری کلمات از مدل زبانی برت استفاده شده و پس از آن یک لایه دستهبند دودویی قرار دادهشده است.

برروی دیتاست TREC CAsT، این مدل به دقت F1 برابر با ۷۸.۵ درصد رسیده است.
جمعبندی
در این پست به بررسی امر بازنویسی سؤالات که در راستای کمک به پرسش و پاسخ مکالمهای ارائه شده است پرداختیم و با دو تا از معماریهای بازنویسی سؤالات آشنا شدیم و دقت آنها روی دیتاستهای بازنویسی سوالات را از نظر گذراندیم. همچنین به عنوان جمعبندی، طبق آزمایشهای انجام شده توسط [4] بر روی هر دو این مدلها، روش دستهبندی کلمات، برای دادگان CAsT 2020 بهتر از روش ترنسفورمر ++ عمل میکند.
ارجاعها
[1] Elgohary, A., Peskov, D., Boyd-Graber, J.: Can you unpack that? learning to rewrite questions-in-context. In: EMNLP-IJCNLP (2019)
[2] Vakulenko, S., Longpre, S., Tu, Z., Anantha, R.: Question rewriting for conversational question answering. In: WSDM (2021)
[3] Voskarides, N., Li, D., Ren, P., Kanoulas, E., de Rijke, M.: Query resolution for conversational search with limited supervision. In: SIGIR (2020)
[4] S. Vakulenko, N. Voskarides, Z. Tu, and S. Longpre, A Comparison of Question Rewriting Methods for Conversational Passage Retrieval. arXiv, 2021. doi: 10.48550/ARXIV.2101.07382.