

مقدمه
در این پروژه دو محصول چدید NVIDIA در حوزه ی پردازش گفتار را بررسی می كنیم محصول اول RIVA NVIDIA نام دارد كه برای تبدیل متن به گفتار و گفتار به متن مورد استفاده قرار می گیرد، یك از مشكلات این ابزار برای ما عدم وجود مدل از پیش آموزش دیده شده ی فارسی است اما با استفاده از ابزار Toolkit TAO NVIDIA می توان مدل جدیدی برای زبان فارسی آموزش داد.
و محصول دیگر فریم ورك NeMo NVIDIA نام دارد كه مشابه RIVA NVIDIA بخشی از پلتفرم AI NVIDIA است و ابزاری برای آموزش مدل های هوش مصنوعی در حوزه پردازش گفتار است NeMo NVIDIA مجموعه های جداگانه ای برای مدل های تشخیص خودكار گفتار(ASR) ، پردازش زبان طبیعی (NLP) و مدل های تبدیل متن به گفتار (TTS) دارد.
در این پروژه ما با استفاده از ابزارهای موجود NeMo NVIDIA و فریمورك [PyTorch] مدل تبدیل متن به گفتار برای زبان فارسی آموزش می دهیم.
NVIDIA RIVA
برای استفاده از فرم ورك RIVA NVIDIA پیش نیازهایی تعریف شده است از جمله:
- دسترسی و عضویت در NGC NVIDIA
- دسترسی به یك سری از كارت گرافیك های خاص NVIDIA
- نصب Docker با پشتیبانی از GPUs NVIDIA
- دسترسی بهKey ـ API ـ NGC و Organization ـ NGC به منظور فعالسازی Riva Enterprise metrics collection
كه در این موارد با چالش هایی مواجه شدیم از جمله عدم دسترسی به NGC NVIDIA به دلیل محدودیت ها و تحریم های از سوی NVIDIA علیه كاربران ایرانی و همچنین عدم دسترسی به كارت گرافیك های موردنظر جهت آموزش مدل، كه باعث شد در این مرحله از NVIDIA RIVA صرف نظر كرده و از NeMo NVIDIA استفاده كنیم.
NVIDIA NeMo
همان طور كه در مقدمه اشاره شد NeMo NVIDIA ابزار ها و مجموعه های جداگانه ای (Collections) جهت ساخت و توسعه مدل برای حوزه های مختلف پردازش گفتار در اختیار توسعه دهندگان قرار داده است در ابتدا پس از نصب Toolkit NeMo از گیت هاب فریمورك NeMo NVIDIA كار را با آزمایش و استفاده از مدل انگلیسی از پیش آموزش داده شده آغاز كردیم.
با استفاده از كد:

می توان مدل های موجود از پیش آموزش داده شده را مشاهده كرد. یك مدل متن به گفتار بر اساس معماری TacoTron2 برای زبان انگلیسی از بین مدل های از پیش آموزش داده شده انتخاب كرده و آن را در متغیر model ذخیره می كنیم.

پس از آن spectrogram آن را با استفاده از كتابخانه ی SpectrogramGenerator تولید می كنیم توابع كلیدی این كتابخانه: parse كه یك رشته از متن را گرفته و tensor token آن را تولید می كند و spectrogram generate كه tensor token را می گیرد و spectrogram آن را را تولید می كند.

در آخر با استفاده از كتابخانه Vocoder و مدل از پیش آموزش داده شده ی آن بر اساس معماری hifigan ، spectrogram تولیدی را به صوت تبدیل می كنیم.
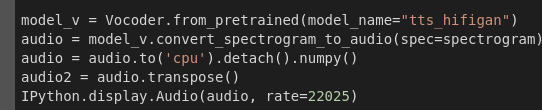
پس از آزمایش مدل از پیش آموزش داده شده برای زبان انگلیسی به سراغ آموزش مدل برای زبان فارسی می رویم.
ما در این پروژه برای مدل خود از معماری TacoTron2 استفاده می كنیم در ابتدا به جمع آوری دیتاست های فارسی می پردازیم. پس از جمع آوری دیتاست های مورد نظرمان با استفاده از كتابخانه ی Lightning PyTorch و ابزار Hydra آموزش مدل خود را شروع می كنیم كه كد پایتون برنامه ی ما كه برای آموزش مدل استفاده می شود در زیر مشاهده می كنید.
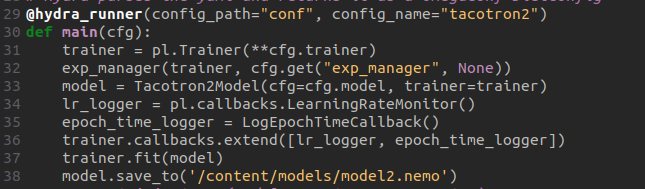
و همچنین فایل كانفیگ كه برنامه از آن استفاده می كند دارای پارامترهای مهمی از جمله و train dataset آدرس ، max epochs ، is phonem ، batch size ، sample rate dataset validation است كه مطابق با دیتاست خود می توان مقادیر آن را تغییر داد در آخر با اجرا كردن برنامه ی پایتون مورد نظرمان كه در بالا كد آن قرارگرفته بود شروع به آموزش مدل می كنیم و نتیجه ی آن را مانند آزمایش مدل از پیش آموزش داده شده آزمایش می كنیم. همچنین برای آموزش مدل NEMO NVIDIA از یك g2p Normalization استفاده می كند كه برای دریافت نتیجه ی بهتر می توان آن را نیز برای زبان فارسی تغییر و مطابقت داد.
نتيجه گيری
ما در این پروژه با استفاده از ابزارهای موجودی كه NVIDIA برایمان در فریمورك NeMo فراهم آورده است توانستیم مدلی جدید برای زبان فارسی در حوزه ی آموزش تبدیل متن به گفتار آموزش دهیم.