


مقدمه
تشخیص خودكار گفتار (ASR) می تواند گفتار را به متون قابل خواندن توسط كامپیوتر ترجمه كند. در كنترل ترافیك هوایی(ATC) راه اصلی ارتباط بین كنترلرهای ترافیك هوایی(ATCo) و خلبانان گفتار رادیویی است. تشخیص خودكار گفتار برای ترجمه گفتار كنترلرهای ترافیك هوایی و خلبان به سیستم ترافیك هوایی معرفی شده است كه می تواند برای كاهش بار كاری و اطمینان از ایمنی پرواز استفاده شود. كارهای اخیر بر روی پیش آموزشی تحت نظارت خود(training-pre supervised-self) بر روی داده های گفتاری بدون برچسب در مقیاس بزرگ برای ساخت مدل های صوتی (AM) قوی (E2E) متمركز شده است كه بعداً می توانند در كارهای downstream مانند تشخیص خودكار گفتار تنظیم شوند. ما سناریویی را با تجزیه و تحلیل استحكام مدل های 0.Wav2Vec2 و R-XLS در ASR downstream برای حوزه ارتباطات كنترل ترافیك هوایی هدف قرار می دهیم.
ATC با هدایت هواپیما در هوا و روی زمین از طریق ارتباطات صوتی بین كنترلرهای ترافیك هوایی (ATCOs) و خلبانان سر و كار دارد. اینها توسط یك دستور زبان و واژگان كاملا تعریف شده كنترل می شوند كه باید برای فراهم كردن یك پرواز امن و قابل اعتماد از ترافیك هوایی و در عین حال پایین نگه داشتن هزینه های عملیاتی تا حد امكان رعایت می شوند. علی رغم علاقه به یك سیستم تشخیص گفتار خودكار برای ارتباطات كنترل ترافیك هوایی، یك سیستم ً كاملا كاربردی در بازار وجود ندارد كه از جمله دلایل آن می توان به این دو اشاره كرد:
- كارایی های پایین سیستم های معرفی شده (به جای تأخیر در انجام وظایف آنها، بهره وریها ATCO را افزایش می دهد) در نتیجه اهمیت تشخیص درست دستورات و كاهش خطای تشخیص دستورات خلبان (CA-WER (call-sign word-error-rate)
- فقدان داده های گفتاری مشروح در مقیاس بزرگ (كمتر از ۵۰ ساعت داده های گفتاری منبع باز) و هزینه تولید بالای آن، آن را تقریبا غیرعملی می ساز
انگيزه انجام پژوهش
پژوهشهای ما سناریوی عدم تطابق دامنه را با پاسخ به سه سوال زیر پوشش می دهد:
عملكرد مدل های E2E از پیش آموزش دیده در حوزه های جدیدی مانند ATC چقدر بی نقص و قدرتمند هستند؟
نتایج ما (جدول ۳) تأیید می كند كه مدل های انتها به انتها یا E2E كه توسط-supervised-self learning یا SSL پیش آموزش شده اند (trained-pre) (مانند Wav2Vec2) یك نمایش قوی از گفتار را یاد می گیرند. تنظیم دقیق (tune-fine) در یك كار downstream) مانند ASR (از نظر محاسباتی ارزان تر از آموزش از ابتدا است، و برای دستیابی به نتایج قابل مقایسه با ASR مبتنی بر روش هیبریدی، به داده های درون دامنه(domain-in) كمتری نیاز دارد. ما همچنین این فرضیه را مطرح می كنیم كه مدل های چند زبانه E2E مانند R-XLS در داده های گفتاری ATC كه حاوی انگلیسی لهجه دار (یعنی مجموعه هایTest LiveATC وTest-ATCO2) هستند، بهتر هستند. به دلیل بازنمایی كلی گفتار آموخته شده در طول SSL.
چه مقدار داده برچسب دار ATC (اعم از صوتی و متنی) در مرحله تنظیم دقیق مورد نیاز است تا نتایج قابل مقایسه با مدل های مبتنی بر هیبریدی باشد؟
ما یك مطالعه مقایسه ای از ۵ دقیقه (یادگیری چند شات) تا حدود ۱۵ ساعت گفتار برچسب دار (یعنی از ۱۰۰ تا ۱۵ هزار گفته) انجام می دهیم. علاوه بر این، ما افزایش عملكرد به دست آمده از رمزگشایی با search beam را با استفاده از یك مدل زبان درون دامنه (LM) به جای رمزگشایی بر اساس مدل حریصانه یا greedy بررسی می كنیم.
حتی اگر مدل های Wav2Vec2 و R XLS از نظر طراحی قابلیت streaming ندارند، آیا چنین مدل های E2E می توانند در برنامه های بلادرنگ مانند ATC استفاده شوند؟ بسیاری از برنامه های كاربردی (به عنوان مثال، ATC ) به موتورهای streaming ASR نیاز دارند. ما تاخیر عبور و رمزگشایی هر دو مدل E2E ،یعنی Wav2Vec2 و R-XLS را در طول استنتاج ارزیابی می كنیم.
دادگان
ما روی دو مجموعه آموزشی و چهار مجموعه تست به زبان انگلیسی با لهجه های مختلف آزمایش می كنیم (جدول ۱ ).به این نكته توجه داریم كه جمع آوری داده های كنترل ترافیك هوایی به دلیل شرایط نویز، حریم خصوصی داده ها، میزان گفتار و لهجه زبان، چالش برانگیز و پرهزینه است.
NATS و ISAVIA :داده های گفتاری توسط ارائه دهندگان خدمات ناوبری هوایی (ANSP) برای پروژهHAAWAII جمع آوری و حاشیه نویسی می شود. دو مجموعه داده عبارتند از:
- رویكرد لندن (NATS)
- ایسلندی (ISAVIA)
در مجموع، ۳۲ ساعت داده های رونویسی دستی برای آموزش و ۲ ساعت برای آزمایش وجود دارد. هر دو مجموعه داده به عنوان گفتار با كیفیت خوب و با فركانس ۸ كیلوهرتز فهرست بندی می شوند. برای دیدن جزئیات بیشتر به جدول ۱ مراجعه كنید.
ATCO2-Test :مجموعه توسعه و ارزیابی موجود به عنوان منبع باز و ارائه شده در Interspeech در سال ۲۰۲۱ .داده ها از ارتباطات كنترل ترافیك هوایی از فرودگاه های مختلف واقع در استرالیا، جمهوری چك، اسلواكی و سوئیس تشكیل شده است. این دیتاست حاوی تركیبی از ضبط های پر سر و صدا و با لهجه انگلیسی است. این اولین مطالعه ای است كه تشخیص خودكار گفتار انتها به انتها(ASR E2E) را برای Test-ATCO2 ارزیابی می كند، به عنوان مثال، نرخ خطای كلمه یاWERهای فهرست شده در اینجا می توانند به عنوان خطوط پایه برای تحقیقات آینده مورد استفاده قرار گیرند.
Test-LiveATC :مجموعه آزمایشی از داده های LiveATC4 ضبط شده از كانال های رادیویی VHF در دسترس عموم، به عنوان بخشی از پروژه ATCO2 جمع آوری می شود و شامل ضبط های آزمایشی و كنترلر ترافیك هوایی با انگلیسی لهجه دار از فرودگاه های واقع در ایالات متحده، جمهوری چك، است. ایرلند، هلند و سوئیس. ما Test-LiveATC را به عنوان مجموعه داده های گفتاری با كیفیت پایین در نظر می گیریم، یعنی نسبت سیگنال به نویز (SNR ) از ۵ تا ۱۵ دسی بل می رود. (SNR شاخصی كه میزان كیفیت سیگنال را نشان می دهد و SNR بالای ۱۰ الی ۱۵ نشان دهنده كیفیت مقبول است)
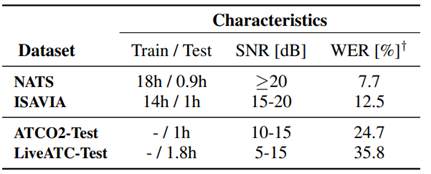
جدول ۱ :ویژگی های دادگان آموزشی و آزمایشی
تشخيص خودكار گفتار
راه اندازی ما بر اساس دو مجموعه داده تنظیم دقیق (tune-fine) شده است. اول، ما از ۳۲ ساعت داده های مشروح از NATS و ISAVIA استفاده می كنیم و ویژگی های آن را در جدول ۱ فهرست می كنیم. در حال حاضر از این مجموعه های تنظیم دقیق به عنوان مجموعه های تنظیم دقیق ۳۲ ساعت و ۱۳۲ ساعت یاد می كنیم.
تشخيص خودكار گفتار مبتنی بر روش هیبریدی
همه آزمایش ها با جعبه ابزار Kaldi انجام می شوند. مدل های پایه از شش لایه كانولوشن و ۱۵ شبكه عصبی تاخیر زمانی فاكتوریزه شده (حدود ۳۱ میلیون پارامتر قابل آموزش) تشكیل شده اند. ما دستورالعمل استاندارد آموزش زنجیره ای MMI-LF s’Kaldi را دنبال می كنیم. ویژگی های ورودی MFCC با وضوح بالا با میانگین نرمال كپسترال آنلاین (CMN) هستند. ویژگی ها با i-vectors گسترش یافته اند. در هنگام رمزگشایی از مدل زبانی APRA سه تایی استفاده می كنیم. این مدل برای ۵ دوره در ۱۳۲ ساعت گفتار كنترل ترافیك هوایی(شامل NATS و ISAVIA) آموزش داده شده است. WER در آخرین ستون جدول ۱ فهرست شده است.
تشخيص خودكار گفتار انتها به انتها
ما نتایج چهار پیكربندی مدل های R-XLS/Wav2Vec2 را گزارش می كنیم كه از فرم پلات HuggingFace واكشی شده اند. از این پس، ما این مدل ها را به عنوان زیر برچسب گذاری می كنیم:

جدول۲ :پیكربندی مدل های R-XLS/Wav2Vec2
همه آزمایش ها از یك مجموعه فراپارامتر(hyperparameter) استفاده می كنند. رمزگذار ویژگی (encoder feature) در كل مرحله تنظیم دقیق به روز نمی شود (روش رایج در سناریوهای با منابع كم). ما هر مدل را برای ۱۰ هزار گام با یك مرحله گرم كردن(up-Warm (۵۰۰ گامی تنظیم می كنیم (تقریباً ۵ درصد از كل به روز رسانی ها). سرعت یادگیری به صورت خطی تا 4-1e در طول گرم كردن افزایش می یابد، سپس به صورت خطی تحلیل می رود. ما هر مدل را روی 3090 RTX GeForce NVIDIA با اندازه دسته (batch (۷۲) اندازه دسته ۲۴ ،انباشتگی گرادیان ۳) تنظیم دقیق می كنیم. ما از واژگان مبتنی بر كاراكتر با ابعاد ۳۲ استفاده می كنیم.
تقويت داده (data augmentation)
توالی ورودی را با احتمال 075.0 = p و 12 = M فریم متوالی ماسك می كنیم. ما همچنین از شاخص فعال سازی ۰ .۰۵ استفاده می كنیم. این فراپارامترها از پیاده سازی اصلی Wav2Vec2 پیروی می كنند.
مدل زبانی (language model)
ما همه رونوشت های متنی را به هم متصل می كنیم و مدله ای زبانی ARPA ۲ ،۳ یا ۴تایی را آموزش می دهیم. مدل های زبانی با همجوشی كم عمق با رمزگشای CTC مبتنی بر پایتون ادغام می شوند. مدل زبانی ۴ تایی به طور سیستماتیك در مقایسه با ۲ تایی ها نتایج بهتری در همه مجموعه های آزمایشی انجام دادند (حدود ۲ درصد WERR نسبی). ما نتایج را فقط با مدل زبانی ۴تایی گزارش می كنیم. همچنین ما 5.0 = α و 5.1 = β را تنظیم كردیم، كه مربوط به طول و وزن نرمال سازی امتیاز مدل زبانی است. اندازه beam را روی ۱۰۰ قرار می دهیم.
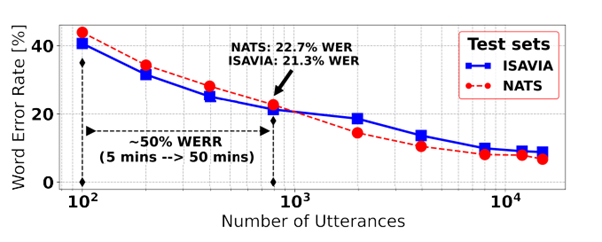
شكل ۱ :تاثیر اندازه داده تنظیم دقیق روی نرخ خطای كلمه
آموزش افزایشی
با موفقیت اخیر مدل های انتها به انتها كه با آموزش تحت نظارت خود از پیش آموزش داده شده اند، تعیین مقدار داده ای كه یك مدل واقعاً برای انجام مؤثر در یك كار downstream نیاز دارد، از اهمیت ویژه ای برخوردار است. این امر به ویژه برای كارهای با منابع اندك مانند كنترل ترافیك هوایی كه چند ده ساعت داده برچسب گذاری شده برای آموزش یا تنظیم دقیق در دسترس است، بسیار مهم است. در اكثر این نمونه ها، داده های یك فرودگاه به فرودگاه های دیگر به خوبی تعمیم نمی یابد و این به دلیل تغییر دامنه قابل توجه AM (لهجه، نرخ بلندگو)، و همچنین تغییر دامنه LM) تسلط هواپیماهای مختلف و دستورات مختلف بسته به فرودگاه) می باشد. ما عملكرد مدل را در مقابل اندازه های مختلف داده های تنظیم دقیق تحلیل می كنیم. ما با چهار سناریو یادگیری چند شات با كمتر از یك ساعت (نزدیك ۱۰۰۰ عبارت) داده های تنظیم دقیق آزمایش كردیم. در مجموع، ۹ مدل فقط بر روی NATS (خط چین قرمز) یا فقط بر روی داده های ISAVIA (خط مستقیم آبی) تنظیم شده اند كه در شكل ۱ نشان داده شده است (محور x به تعداد عبارت های استفاده شده در هنگام تنظیم دقیق در مقیاس لگاریتم اشاره دارد)
هر مجموعه آزمایشی (یعنی NATS و ISAVIA ) فقط از داده های درون دامنه خود در هنگام تنظیم دقیق و ارزیابی استفاده می كند. گفته های ۱۰۰ ،۰۰۰،۱ و ۰۰۰،۱۰ به ترتیب تقریباً ۵ دقیقه (چند شات)، ۱ ساعت و ۱۰ ساعت است.
ارزیابی streaming
مدل های Wav2Vec2 و R-XLS با قابلیت های streaming طراحی نشده اند، اما می توان از قابلیت های GPU در طول استنتاج برای ارائه رمزگشایی بلادرنگ استفاده كرد. برای آزمایش این فرضیه، روش زیر را انجام می دهیم: صوت را به n تكه با اندازه های افزایشی تقریبا به اندازه ۳۰۰ میلی ثانیه تقسیم می كنیم. سپس هر تكه افزایشی را به مدل منتقل می كنیم و این كار را برای همه تكههای صوت انجام می دهیم. در نهایت، میانگین زمان مورد نیاز شبكه برای رمزگشایی تمام تكه های یك صوت معین را اندازه گیری می كنیم. ما این فرآیند را روی ۱۰۰ نمونه تصادفی از مجموعه های آزمایشی تكرار می كنیم و میانگین زمان تأخیر را گزارش می كنیم. ما تأثیری را كه در راه اندازی streaming بر روی WER ایجاد شده است در نظر نمی گیریم.
نتايج تجربی
در این مقاله، ما فرض می كنیم كه مدل های انتها به انتها آموزش دیده شده تحت نظارت خود، یك نمایش قوی از گفتار را یاد می گیرند و در وظایف downstram مانند تشخیص خودكار گفتار تك زبانه یا چند زبانه به خوبی عمل می كنند. ما یافته های خود را با پاسخ به سؤالات زیر تقسیم كردیم:
شكستن پارادايم، مبتنی بر روش هیبریدی يا انتها به انتها؟
اگرچه مدل سازی سیستم تشخیص خودكار مبتنی بر روش هیبریدی برای چندین سال پیش فرض بوده است، اما موج جدیدی از معماری های انتها به انتها كه توسط آموزش تحت نظارت خود برای تركیب اشتراكی AM و LM آموزش داده شده اند جای آن را گرفته اند. ما مدل های انتها به انتها را با بهترین روش مبتنی بر هیبریدی كه با مجموعه تنظیم دقیق ۱۳۲ ساعته در Kaldi آموزش داده شده است مقایسه می كنیم (ردیف اول جدول ۳).
براي مدل سازی انتها به انتها:
- 60k-L-w2v2 را برای مجموعه های آزمایشی NATS و ISAVIA انتخاب می كنیم، كه فقط در مجموعه ۳۲ ساعته، یعنی داده های درون دامنه، به خوبی تنظیم شد.
- سپس w2v2-XLS-R+ برای مجموعههای تست LiveATC-Test و ATCO2-Test ، كه بر روی ۱۳۲ ساعت از داده های گفتاری كنترل ترافیك هوایی آموزش داده شد، شامل داده های متنوع تر و مشابه مدل مبتنی بر هیبریدی
در نهایت 60k-L-w2v2 ۳۰ درصد كاهش WER نسبی را در NATS و ۴۱ درصد در ISAVIA در مقایسه با روش مبتنی بر هیبریدی به همراه داشت. این بهبود قابل توجه است، حتی اگر مدل پایه بر روی چهار برابر داده های 60k-L-w2v2 آموزش داده شده باشد (جدول ۳ را ببینید).
به طور مشابه، +R-XLS-w2v2( ردیف آخر، جدول ۳ ) در هر چهار مجموعه آزمایشی از مدل مبتنی بر تركیبی پیشی می گیرد، اما در Test-ATCO2 وTest-LiveATC ،دو مورد چالش برانگیز(به دلیل لهجه دار بودن دادگان)، نتایج بسیار قابل توجه است. در مجموع، ۱۹ و ۳۰ درصد WER نسبی درTest-ATCO2 وTest-LiveATC به ترتیب به دست آمد (مقایسه-XLS-w2v2 +R نسبت به روش هیبریدی)
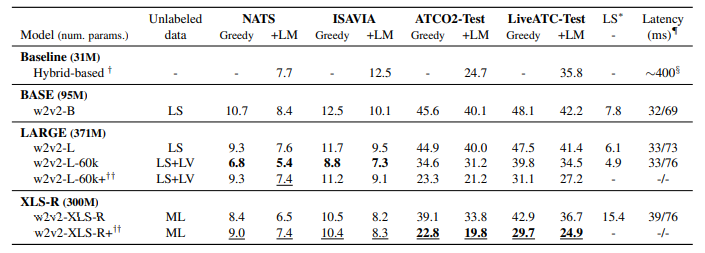
شكل ۲ :WER ثبت شده از چهار مجموعه آزمایشی مطرح شده. WERها به صورت bold و underline به ترتیب مدل هایی اشاره می كنند كه روی داده های ۳۲ ساعته و ۱۳۲ ساعته تنظیم شده اند.
آيا داده هاي افزودهی جزئی در دامنه (domain-in-partly) ،عملكرد سيستم تشخيص گفتار را افزايش میدهد؟
ما به این سوال با مقایسه مدل های تنظیم شده دقیق در مجموعه ۱۳۲ ساعت یا ۳۲ ساعت پاسخ می دهیم. توجه داشته باشید كه NATS و ISAVIA مجموعه های گفتاری كنترل ترافیك هوایی درون دامنه ای تمیز هستند، به عنوان مثال، به عنوان درون دامنه برای ۳۲ ساعت و در غیر این صورت تا حدی درون دامنه(domain-in) در نظر گرفته می شوند (مجموعه ۱۳۲ ساعت). ATCO2 Test و LiveATC-Test را می توان به عنوان مجموعه های پر سر و صدا و تا حدی در دامنه (فرودگاه های مختلف، به عنوان مثال، عدم تطابق صوتی و LM) در نظر گرفت. ما روی-w2v2 60k-L و +60k-L-w2v2 كه به ترتیب در مجموعه های ۳۲ و ۱۳۲ ساعت تنظیم شده اند، تمركز می كنیم. توجه داشته باشید كه نتایج قابل مقایسه ای بین R-XLS-w2v2 و +R-XLS-w2v2 وجود دارد. ما WER را در رمزگشایی حریصانه تجزیه و تحلیل می كنیم تا فقط روی LM+AM مشترك تمركز كنیم. در اینصورت یك تنزل WER برای مجموعه های آزمایشی درون دامنه، برای عمدتا این. كردیم مشاهده ISAVIA: 8.8٪ → 11.2٪ WER و NATS: 6.8٪ → 9.3٪ افزودن داده هایی است كه با NATS و ISAVIA مطابقت ندارند. برعكس، كاهش WER قابل توجهی در مجموعه های دامنه های جزئی وجود دارد، ٪3.23٪ → 6.34: Test-ATCO2 و LiveATC-Test 39.8٪ → 31.1٪
بطور خلاصه مجموعه آزمون NATS با هفت درصد كاهش WER نسبی بدتر نسبت به حالت بدون داده های افزونه، تحت تأثیر افزودن داده های جزئی در دامنه قرار گرفت (این درصد برای ISAVIA حدود یك درصد است). با این وجود، مجموعه های تست چالش برانگیز به طور چشمگیری بهبود یافتند، یعنی Test-ATCO2 ،۴۳ درصد و Test-LiveATC ،۳۳ درصد WER نسبی بهبود داشتند.
مدلهای از پيش آموزش ديده چند زبانه چه كمكی میكند؟
اگر +60k-L-w2v2 و R-XLS-w2v2 را مقایسه كنیم كه از تنظیمات دقیق و رمزگشایی beam serach با مدل زبانی استفاده می كنند، نرخ خطای كلمه نسبی در ISAVIA ،Test-ATCO2 و Test-LiveATC ،به ترتیب ۸ .۸ درصد، ۶ .۶ درصد و ۸ .۵ درصد می باشد (بدون پیشرفت در NATS) .در عین حال بهبود قابل توجهی در چالش برانگیزترین مجموعه های تست (-5: SNR dB 10) كه حاوی گفتار انگلیسی لهجه دار هستند، به عنوان مثال، Test-ATCO2 و-LiveATC Test مشاهده می شود. بنابراین، مدل های پیش آموزش شده چند زبانه، در مقایسه با مدل های پیش آموزش شده تك زبانه، عملكرد كمی را افزایش می دهند.
براي تنظيم دقيق مدلهای Wav2Vec2 و R-XLS به چه مقدار داده نياز است؟
ما تأثیر مقادیر مختلف از داده های تنظیم دقیق را در طول مرحله تنظیم دقیق روی نرخ خطاهای كلمه، بررسی می كنیم (شكل ۱ ).همه آزمایش ها بر اساس قوی ترین مدل انتها به انتها از جدول ۳ هستند، یعنی WER 60K-L-w2v2 ها با رمزگشایی حریصانه به دست می آیند، یعنی هیچ مدل زبانی یا اطلاعات متنی صریحا اضافه نمی شود. ما ۱۸ مدل را با تغییر دادن مجموعه داده های آموزشی (یا NATS یا ISAVIA) و مقدار نمونه ها، تنظیم دقیق می كنیم. ما در ابتدا سناریوی یادگیری چند شات (بدترین حالت) را آزمایش كردیم، كه در آن تنها ۱۰۰ گفته برچسب دار (۵ دقیقه) برای تنظیم دقیق استفاده شد، و ۴۰WER درصد برای ISAVIA و ۴۳ .۹ درصد برای NATS به دست آورد. علاوه بر این، ۵۰ كاهش WERنسبی با افزایش مقیاس داده های تنظیم دقیق به ۵۰ دقیقه (۸۰۰ گفته) به دست می آید. به طور دقیق، ٪7.22٪ → 9.43 NATS و WER٪ 3.21٪ → 6.40 ISAVIA .در نهایت، اگر از تمام داده های موجود (حدود ۱۴ ساعت) استفاده شود، به ترتیب به ۸ .۸ درصد و ۶ .۸ درصد WER برای ISAVIA و NATS می رسیم. این نشان دهنده یك WER نسبی ۸۰ درصد در مقایسه با حالت اولیه یا بدترین حالت (۱۰۰ عبارت) است. از دیگر نتایج اینكه با حدود ۸ ساعت (حدود ۸۰۰۰ عبارت) 60K-L-w2v2 عملكرد تشخیص خودكار گفتار مبتنی بر هیبریدی را شكست می دهد (كه از چهار برابر بیشتر داده های آموزشی) استفاده می كند.
آیا تشخیص خودكار گفتار time-realدر معماری های انتها به انتها، به عنوان مثال، Wav2Vec2 امكان پذیر است؟ ما هر شش مدل از جدول ۳ را در حالت streaming در یك پردازنده گرافیكی Ti 1080 GTX GeForce NVIDIA میان رده آزمایش می كنیم. تأخیرات شامل گذر رو به جلوی مدل، رمزگشایی search beam و رمزگذاری (detokenization) است. نتایج اصلی در جدول ۳ (ستون آخر) گزارش شده است. تأخیر گذر رو به جلو مدل هایWav2Vec2 و R-XLS به طور كلی كمتر از ۱۰۰ میلی ثانیه است. به عنوان مثال، مدل های -L/L/B-w2v2 60k و R-XLS-w2v2 زمانی كه رمزگشایی حریصانه انجام می دهند تأخیر كمتر از ۴۰ میلی ثانیه دارند. اگر از رمزگشایی search beam با مدل زبانی ۴تایی استفاده شود، تاخیر تقریباً دو برابر می شود. این تحقیق تخریب WER ناشی از استفاده از مدل های انتها به انتها در حالت streaming را پوشش نمی دهد.
نتيجه گیری
این مقاله استحكام مدل های Wav2Vec2 از پیش آموزش دیده را در downstream برای كنترل ترافیك هوایی ارزیابی می كند. آزمایش های ما پیشرفت های بزرگی را در تشخیصWav2Vec2 و R-XLS در مقایسه با تشخیص خودكار گفتار مبتنی بر هیبریدی نشان می دهند. از نظر كمی، بین ۲۰ تا ۴۰ درصد كاهش WER نسبی در مجموعه های آزمایشی ISAVIA ،NATS و از مجموعه های چالش برانگیز چند لهجه ای مانند Test- ATCO2 وTest-LiveATC به دست آمد. علاوه بر این، ما نشان دادیم كه Wav2Vec2 از پیش آموزش دیده، یك مرحله تنظیم دقیق سریع با مقادیر كمی از داده های سازگار را امكان پذیر می كند، به عنوان مثال، تنظیم دقیق ۵ دقیقه ای، مدلی كه WERهای ۴۰ درصد برای ISVAIA و ۴۳ .۹ درصد را برای NATS به دست می آورد. علاوه بر این، ما نشان دادیم كه حداقل ۴ ساعت از داده های درون دامنه، WER قابل قبولی در حدود ۱۰ درصد برای ضبط های ISAVIA و NATS ارائه می كنند و با استفاده از داده های دو برابر بیشتر (یعنی ۸ ساعت) عملكردشان از تشخیص خودكار گفتار مبتنی بر هیبریدی پیشی می گیرد. در نهایت، ما اعداد قابل رقابتی در تأخیر برای مدل های Wav2Vec2 و R-XLS در یك GPU میان رده به دست آوردیم، یعنی حدود ۸۰/۴۰ میلی ثانیه با مدل زبانی در رمزگشایی جستجوی حریصانه و search beam.
مراجع
J. Zuluaga-Gomez et al., “How Does Pre-trained Wav2Vec2.0 Perform on Domain Shifted ASR? An Extensive Benchmark on Air Traffic Control Communications.” arXiv, Mar. 31, 2022. doi: 10.48550/arXiv.2203.16822.