


مقدمه
مدل كانفورمر (Conformer) مدل جدیدی در حوزه پردازش صوت است كه شبكه های Transformerی را باCNN تركیب كرده است. به نظر میرسد این مدل كار ارزشمندی باشد ولی به دلیل ماهیت ساختاری آن نتوانسته بر روی مدل های شركت HuggingFace كار بكند و مستندات كمتری درباره آن وجود دارد.
در این پروژه ابتدا مقاله ی اصلی كانفورمر بررسی میشود، سپس مدل اولیه ای بر روی زبان انگلیسی از ابتدا آموزش داده میشود و در آخر هم تلاش بر این بوده كه برای زبان فارسی بتوانیم مدلی داشته باشیم. با توجه به وجود مدل های رقیب برای كانفورمر، در این مقاله مدل ContextNet هم برای مقایسه بررسی میشود.
دیتاست استفاده شده برای آموزش اولیه روی زبان انگلیسی دیتاست AN4 است كه با با آموزش اولی و بدون جست و جو برای پارامترهای بهینه و یا استفاده از مدل زبان، خطای 27.0 = WER را داشتیم. در ادامه برای آموزش مدل فارسی از دیتاست Voice Common Mozilla استفاده شد كه شامل ۶ ساعت صوت و متن فارسی است.
در انجام آزمایش ها از جعبه ابزار Nemo و كتابخانه های مرتبط با آن استفاده شده. Nemo كتابخانه با انواع مدل های پردازش صوت است كه توسط شركت Nvidia توسعه داده شده. مدل های این كتابخانه روی زبان انگلیسی با دیتاستی چندین هزار ساعته آموزش داده شده اند و اپن سورس هستند. با توجه به محدودیت های سخت افزاری موجود و عدم تخصیص سرور برای آموزش مدل، آموزش این مدل كامل نشد ولی كد آموزش تكمیل شده و همینطور در اولین تلاش ها برای آموزش به خطای 62.0 = WER برای زبان فارسی رسیدیم. مشخصا این خطا مناسب نیست ولی آموزش كامل انجام نشده و جست و جویی هم برای انتخاب پارامتر بهینه صورت نگرفته است. در ادامه هم تاثیرات انتخاب پارامتر های مختلف، مدل های مختلف و همینطور نكاتی برای ادامه كار بیان میشود.
بررسی مدلهای Conformer و ContextNet
مدل های Conformer و ContextNet هر دو مدل های تبدیل وویس به متن هستند و هر دو ساختار ترانسفورمری دارند. تفاوت اصلی این دو مدل در نحوه انجام انكودینگ است. در ادامه ابتدا با بررسی مقاله [۱] ساختار مدل جدید كانفورمر را میبینیم. سپس مقاله [۲] را بررسی میكنیم و با ساختار یكی از رقیب های اصلی كانفورمر آشنا میشویم.
مدل Conformer
شبكه های ترانسفورمری در چند سال اخیر موفقیت چشم گیری به عنوان مدل های پردازش صوت داشته اند. مزیت این مدل ها، توانایی درك ارتباطات كلی بین كلمات است (content-based global interactions) .این توانایی در مقابل توانایی بالای مدل های مبتنی بر شبكه های عصبی كانولوشنی برای درك ویژگی های محلی جملات است.
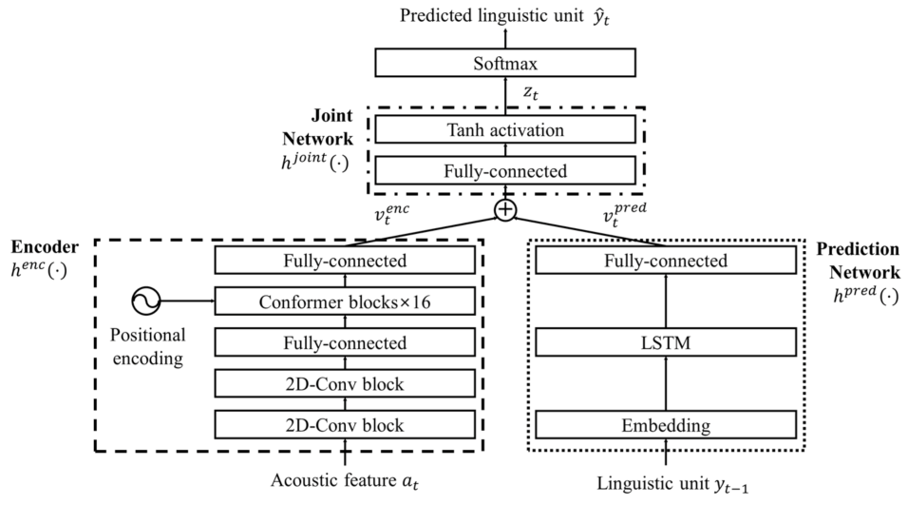
شكل ۱ :ساختار كلی یك مدل كانفورمر
در مدل كانفورمر تلاش بر این است كه با تركیب هر دوی این رویكردها، مدلی با توانایی درك ویژگی های كلی و محلی ساخته شود. اتكا به صرفا شبكه های عصبی برای درك ویژگی های كلی محدودیت های واضحی مثل نیاز به تعداد لایه زیاد وجود دارد. راه حل مناسبی برای این موضوع، استفاده از مكانیزم توجه است كه در حال حاضر به طور گسترده در مدل های مبتنی بر ترانسفورمر استفاده میشود.
ساختار مدل Transducer-Conformer معرفی شده در [۱] از یك انكودر كانفورمر و یك دیكودر یك لایه LSTM نشكیل شده. انكودر كانفورمر را در شكل ۱ میبینیم. انكودر ابتدا با روش های معمول مدل های مشابه مثل انجام كانولوشن و Augmentation Spectogram ،صوت ورودی را پردازش میكند. در ادامه خروجی حاصل از پردازش صوت وارد بلوك كانفورمر میشود. تفاوت اصلی انكودر این مدل با مدل های مشابه، استفاده از بلوك كانفورمر به جای ترانسفورمر است. بلوك كانفومر از چهار ماژول پشت هم تشكیل شده. یك ماژول خود توجهی چند سر و یك ماژول كانولوشن كه توسط دو لایه forward-feed احاطه شده اند. ایده استفاده از دو لایه به جای یك لایه از مدل ارائه شده در [۳] الهام گرفته شده و نتیجه بهتری میدهد. خطا های ارائه شده در مرجع [۱] در شكل ۲ آمده است. میبینیم خطای مدل كانفورمر با سایز بزرگ كمترین مقدار بین مدل های كانفورمر و همینطور بین تمامی مدل های بررسی شده است. همچنین میبینیم كه افزایش سایز مدل كانفورمر باعث بهبود دقت مدل میشود.
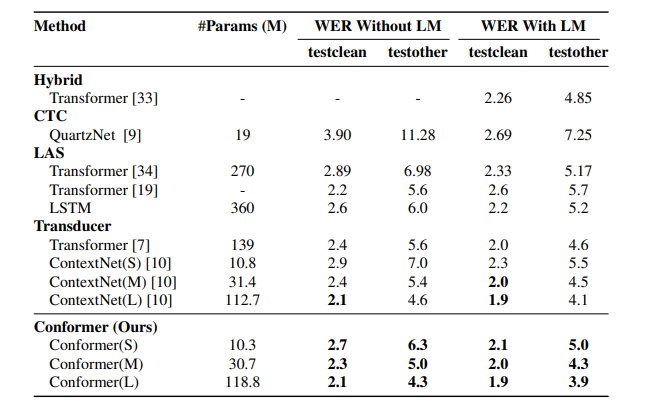
شكل ۲ :خطای انواع مدل های كانفورمر و ContextNet
مدل ContextNet
برای درك بهتر مدل كانفورمر و مقایسه آن با دیگر مدل های ارائه شده، در این قسمت مدل ContextNet را بررسی میكنیم. همانند مدل كانفورمر، مدل ContextNet هم با هدف درك ارتباطات بین كلمات دور از هم ساخته شده. رویكرد این مدل استفاده از ماژول squeeze-and-excitation (SE) است كه در [۴] معرفی شده. عملكرد این ماژول به این صورت است كه برای درك تعاملات بین كلمات دور از هم، ابتدا تمام خروجی های حاصل از عبور پنجره كانولوشن از روی ورودی را در یك بردار ذخیره میكند و سپس با انجام ضرب، این بردار را با بردار های ویژگی های محلی حاصل از كانولوشن تركیب میكند.
در شكل ۳ ماژول SE را مشاهده میكنیم. در ابتدا با عبور پنجره كانولوشن از روی ورودی، تعدادی بردار داریم كه شامل ویژگی های محلی ورودی هستند. با میانگین گیری روی این بردار ها، یك بردار حاصل میشود. سپس این بردار از دو لایه و تابع فعالسازی عبور میكند و سپس در بردار های خروجی كانولوشن ضرب میشود. ساختار نهایی مدل ContextNet همان مدل Transducer-RNNاست [۵] كه از سه بخش انكودر صوت، انكودر برچسب و یك شبكه مشترك برای دیكود كردن و تركیب انكودرها تشكیل شده. تفاوت مدل با مدل های قبلی در انكودر صوت است كه از مكانیزم توضیح داده شده برای انجام كانولوشن و پیدا كردن ارتباطات بین كلمات تشكیل شده است.
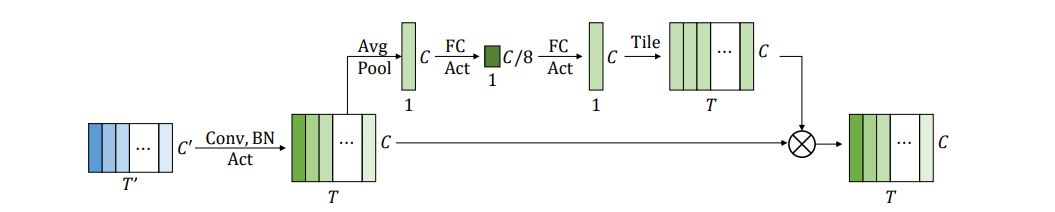
شكل ۳ :ماژول SE
در شكل ۲ هم دقت مدل ContextNet با سایز های مختلف را میبینیم. در بیشتر حالت ها دقت مدل ContextNet اختلاف خیلی كمی با مدل كانفورمر دارد.
آزمايش ها
در ابتدا برای آشنایی با مدل كانفورمر، تلاش كردیم مدل را از ابتدا روی زبان انگلیسی آموزش بدهیم. در آزمایش اول آموزش ها روی مدل های پیش فرض انجام شدند. سپس تغییراتی روی پارامتر های مدل اعمال شد و دوباره آموزش با تنظیمات جدید انجام شد. سپس آموزش روی زبان فارسی با حدود ۶ ساعت داده آموزش یك بار روی مدل پیش فرض و یك بار روی مدل با تنظیمات جدید انجام شد. در ادامه تنظیمات tokenizer تغییر كردند و دوباره آموزش با مدل كانفورمر كوچك پیش فرض انجام شد. در مدل متداول كانفورمر كوچك شبكه ی پیوندی، دیكودر و انكودر به ترتیب دارای ۳۲۰، ۳۲۰ و ۱۷۶ بعد می باشد. مدل كانفورمر دوم با پارامتر های متفاوت در شبكه ی پیوندی، دیكودر و انكودر به ترتیب برابر ۲۸۰ ،۱۴۰ ، ۲۸۰ آموزش داده شد. این مدل ها یك بار با size-batch با اندازه ۱۶ و در ۸۰ epoch با نرخ یادگیری ۵ .۲ آموزش داده شدند. یك بار هم بعد از تغییر تنظیمات پیش پردازش با size-batch با اندازه ۲۱ و نرخ یادگیری ۵ برای شروع و ۲۵ .۰ بعد از ۳۰ epoch آموزش داده شدند.
ابزار مورد استفاده
برای انجام آموزش و آزمایش روی مدل ها، از ابزار Nemo] ۶] استفاده شده است. Nemo مجموعه ای از كتابخانه ها و ماژول ها است كه برای توسعه و آموزش مدل های پردازش صوت استفاده میشود. Nemo به صورت پیش فرض در مدل های آماده خود مدل كانفورمر و همینطور مدل ContextNet را دارد. این مدل ها هم به صورت آموزش دیده روی زبان انگلیسی و هم به صورت مدل بدون آموزش در Nemo موجود هستند.
برای انجام آموزش از محیط Colab Google استفاده شد. در نسخه رایگان این پلتفرم، سروری با پردازنده گرافیكی K80 Nvidia و حافظه گرافیكی 12GB و یا 16GB در به كاربر اختصاص پیدا میكند. زمان استفاده از سرور به چند ساعت در روز محدود شده و به همین دلیل نتوانستیم آموزش را به مدت طولانی انجام دهیم.
ديتاست های مورد استفاده
برای آموزش های اولیه روی مدل زبان انگلیسی از دیتاست AN4 استفاده شد. AN4 دیتاست كوچكی است كه شامل كلیپ های صوتی از خواندن آدرس، اسم و غیره میبااشد [۷] .در ادامه برای آموزش فارسی از نسخه فارسی دیتاست 1.5 Voice Common Mozilla استفاده شد. این دیتاست شامل حدود ۳۰۰ ساعت صوت و متن فارسی است و به صورت متن باز در اختیار عموم قرار دارد. بخش آموزش این دیتاست شامل ۶ ساعت صوت فارسی و متن است كه از این داده ها برای آموزش مدل استفاده شده [۸].
نتايج
- آموزش روی زبان انگلیسی: با مدل پیش فرض كانفورمر كوچك، خطا روی دیتاست AN4 به حدود 47.0=WER رسید. مشخصا این مقدار خطا با توجه به سایز كوچك دیتاست مناسب نبود و این بار پارامترهای مدل روی مقادیر كوچك تری تنظیم شدند. با تنظیمات جدید خطا بعد از ۷۰ epoch به 27.0=WER رسید كه برای مدل اولیه دقت مناسبی بود. پارامتر های این مدل جدید به صورت ابعاد ۶۴ برای انكودر، دیكودر و شبكه پیوندی تنظیم شدند.
- آموزش روی زبان فارسی: در این بخش چندین آزمایش انجام شدند. آزمایش های اولیه با استفاده از یك tokenizer از نوع spe با 35 = size-vocab انجام شدند. در این آزمایش ها مدل پیش فرض كانفورمر بعد از ۸۰ epoch به خطای 72.0=WER رسید و مدل با تنظیمات متفاوت كانفورمر به 88.0=WER .در هر دو حالت میبینیم كه خطای خیلی بالایی داریم. همینطور زمان آموزش هم نسبتا طولانی است و نتوانستیم مدل را روی محیط colab به مدت مناسب آموزش بدهیم.
در این آزمایش ها size-batch روی ۱۶ و نرخ یادگیری روی مقدار ثابت ۵ تنظیم شده بود. در ادامه بعد از بررسی مدل، ابتدا نحوه آموزش به این صورت تغییر كرد كه از مدل آموزش داده شده انگلیسی برای شروع آموزش استفاده شد. همینطور در تنظیمات tokenizer مورد استفاده، اندازه size-vocab به ۱۰۲۴ تغییر كرد. با انجام این تغییرات این بار بعد از ۲۰ epoch به خطای 66.0=WER رسیدیم كه هم از نظر زمانی و هم از نظر خطا نسبت به حالت اولیه بهبود پیدا كرده بود. در اینجا به نظر میرسید كه خطای مدل در حال كاهش نیست و به همین خاطر نرخ یادگیری به ۲۵ .۰ كاهش پیدا كرد. با انجام این كار با انجام آموزش برای ۱۰ epoch بیشتر خطا به 62.0=WER رسید.
مشخصا این بار هم هنوز خطا مناسب نبود ولی با توجه به دسترسی به دیتاست محدود و همینطور عدم تخصیص سرور، به نظر میرسد تنظیمات مدل مناسب هستند و فقط نیاز به آموزش با دیتاست طولانی تر و زمان بیشتر داریم. در شكل ۴ دو نمونه از پیش بینی های مدل را میبینیم. مشخصا برای جمله های ساده تر و كوتاه تر مدل دقت بالاتری دارد و وقتی جمله ها پیچیده باشند دقت مدل مناسب نیست.
مقايسه با مدل ContextNet
به طور كلی مدل ContextNet در آزمایش های انجام شده خطای مشابهی با مدل كانفورمر داشت. در آزمایش های اولیه با مدل های پیش فرض روی دیتاست AN4 ،خطای ContextNet به حداقل ۵ .۰ رسید. در ادامه كاهش سایز مدل ContextNet با كاهش تعداد فیترها به ۱۲۸، و همچنین كاهش ابعاد لایه های پیش بینی و پیوندی به ۶۴ انجام شد. در این حالت خطا به WER=0.22 رسید.
در ادامه با آموزش روی مدل فارسی، خطای مدل 512-ContextNet كه یكی از انواع پیش فرض مدل در Nemo است به حدود 82.0=WER رسید كه همچنان مقدار مناسبی نبود. البته این آزمایش بدون افزایش اندازه size-vocab در tokenizer مورد استفاده انجام شد. میبینیم كه خطای بالای مدل ویژگی مشتركی بین هر دو نوع مدل است. از این موضوع میتوان حدس زد كه دیتاست كوچك استفاده شده و همینطور عدم تخصیص سرور برای انجام آموزش طولانی، مشكلات اصلی در آزمایش ها بوده اند.
بررسی پارامترها با توجه به مطالعات و آزمايش ها
به طور كلی پارامترهای موثر به سه دسته تقسیم میشوند:
پارامتر های پیش پردازش: اینجا پارامتر پیش پردازشی كه بیشترین تاثیر روی خطای مدل را داشت عدد Size-Vocabدر Tokenizer مورد استفاده بود. ابتدا Size-Vocab روی حدود ۳۰ تنظیم شده بود كه معادل داشتن دایره لغاتی است كه فقط شامل حروف الفبا میشود. ولی با افزایش سایز دایره لغات، كلمات و حروف پشت هم پرتكرار هم میتوانند به صورت مجزا و مستقل در نظر گرفته بشوند.
پارامتر های مدل: پارامتر های مدل شامل پارامتر های انكودر، دیكودر و شبكه پیوندی می شود. با آزمایش های انجام شده به خصوص روی دیتاست AN4 میبینیم كه برای داده كم نیاز به كاهش همه پارامتر های مدل داریم. با افزایش داده آموزش مورد استفاده، نیاز به استفاده از مدل با سایز بزرگتر داریم. همینطور دقت میكنیم كه تعداد پارامتر های انكودر مدل كانفورمر بیشترین تاثیر را روی سایز مدل دارد و برای داشتن مدل با حجم معقول نیاز به كنترل تعداد پارامترهای این مدل داریم.
پارامتر های آموزش دهنده: در این قسمت پارامتر هایی مثل نرخ یادگیری و size-batch را داریم. مقدار پیش فرض برای نرخ یادگیری كانفورمر ۵ است كه عدد بزرگی است.

شكل ۴ :دو نمونه از پیش بینی های مدل كانفورمر. میبینیم برای جمله كوتاه تر دقت بهتری داریم.
طبق آزمایش های مختلفی كه انجام دادیم بعد از حدود ۲۰ epoch نیاز به كاهش نرخ یادگیری داریم. همینطور در حالت پیش فرض نرخ یادگیری كاهش پیدا نمیكند كه باز هم طبق آزمایشات انجام شده نتیجه مطلوبی نمی دهد. همینطور طبق جست و جوی انجام شده مدل موجود در ابزار Nemo با size-batch حداقل ۲۵۶ آموزش داده شده [۹] كه عدد بسیار بزرگتری از مقدار استفاده شده در آزمایشات ما است. افزایش این عدد به بیش از ۲۱ كه در آزمایش های ما انجام شد نیاز به حافظه گرافیكی بزرگتر از حافظه تخصیص یافته در Colab داشت و به همین دلیل نتوانستیم این عدد را روی مقدار بزرگتری تنظیم كنیم. این موضوع میتواند روی خطای بدست آمده را به طور قابل توجهی تحت تاثیر قرار بدهد چون size-batch تخمینی از جهت مناسب برای حركت در الگوریتم descent-gradient می دهد و اگر این تخمین به اندازه كافی دقیق نباشد ممكن است به نقطه بهینه نرسیم [۱۰].
نتيجه گيری
با آزمایش های انجام شده میبینیم كه خطای مدل ها بالاست. با توجه به سایز دیتاست مورد استفاده كه فقط شامل ۶ ساعت داده آموزش فارسی بود و همینطور با توجه به محدودیت های موجود برای استفاده از سرور، انتظار این موضوع را داشتیم (برای مثال در مستندات Nemo در [۱۱] میبینیم كه دقت مدل ژاپنی آموزش دیده شده روی دیتاست Voice Common Mozilla با چند ساعت داده آموزشی به حداقل خطای حدود 5.0=WER میرسد.) و برای آموزش یك مدل مناسب نیاز به داده های بیشتر و زمان آموزش بیشتر داریم. همینطور دیدیم كه این خطای بالا به مدل كانفورمر محدود نمیشود و مدل ContextNet كه از مدل های رقیب كانفورمر است هم همین خطا ها را داشت. كد های استفاده شده در گزارش در گیت هاب شركت عصر گویش پرداز قرار خواهند گرفت و برای ادامه كار قابل دسترسی هستند. همینطور یك مدل آموزش داده شده با خطای 62.0=WER موجود است كه میتوان از آن برای ادامه آموزش استفاده كرد. به طور كلی به نظر میرسد پارامتر های مدل به درستی تنظیم شده اند و برای داشتن یك مدل مناسب كانفورمر فارسی فقط نیاز به زمان اجرای بیشتر و دیتاست بزرگتر داریم.
مراجع
- Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., &; Pang, R. (2020, May 16). Conformer: Convolution-augmented transformer for speech recognition. arXiv.org. Ret
- Han, W., Zhang, Z., Zhang, Y., Yu, J., Chiu, C.-C., Qin, J., Gu-lati, A., Pang, R., &; Wu, Y. (2020, May 16). ContextNet: Improving convolutional neural networks for automatic speech recognition with Global Context. arXiv.org. Retrieved September 8, 2022, from https://arxiv.org/abs/2005.03191
- Y. Lu, Z. Li, D. He, Z. Sun, B. Dong, T. Qin, L. Wang, and T.-Y. Liu, “Un- derstanding and improving transformer from a multi-particle dynamic system point of view,” arXiv preprint arXiv:1906.02762, 2019.
- J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141.
- A. Graves, “Sequence transduction with recurrent neural networks,” arXiv preprint arXiv:1211.3711, 2012
- https://developer.nvidia.com/nvidia-nemo
- https://huggingface.co/datasets/espnet/an4
- https://commonvoice.mozilla.org/fa
- https://github.com/NVIDIA/NeMo/issues/3288
- https://deeplizard.com/learn/video/U4WB9p6ODjM
- colab.research.google.com/github/NVIDIA/NeMo/blob/stable/tutorials/asr/ASR_CTC_Language_Finetuning.ipynb